
Submitted by Timothy Jones on Mon, 18/02/2019 - 17:48
One of the themes of my research has been and continues to be the exploitation of parallelism in its many forms. I’ve looked into data-level parallelism by improving the performance of SLP by, for example, reducing the number of instructions that are vectorised and (spoiler alert for a future publication) I have a PhD student working on speculative vectorisation. With Sam Ainsworth, formerly my PhD student, now a postdoc, I have published research that exploits memory-level parallelism within the compiler, architecture and in both with a programmable prefetcher. We’ve also looked into taking advantage of parallelism for error detection. However, the first work I did in this area, and the kind of work that people immediately think about when you say the word “parallelism” is the extraction of thread-level parallelism, which I started in 2010 when I went to Harvard for the year to work with David Brooks and joined forces with Simone Campanoni to develop the HELIX automatic parallelising compiler.
For a while I’ve been fascinated with automatic parallelisation and whether we can use it to boost the performance of all kinds of code, especially legacy programs and those for which we don’t have the source. What I really wanted to do was be able to parallelise application binaries and now, with the release of Janus, developed with my PhD student and now postdoc Ruoyu (Kevin) Zhou, we can do just that.
Janus is a same-ISA automatic binary modification framework for parallelisation. It combines static analysis, profile information and runtime speculation to parallelise application binaries during execution. The novelty in Janus is not the parallelisation that is performed, since currently only DoAll loops are parallelised, but firstly that we combine static analysis with dynamic modification through a new intermediate architecture-independent interface, called a rewrite schedule, and secondly that we use speculation to safely parallelise loops even when they contain code that is only discovered at runtime. Let’s consider each of these in turn.
We call our tool Janus after the Roman god of duality, amongst other things (Wikipedia has a list), and he is usually depicted with two faces. For us, this represents the power of harnessing both static analysis and dynamic modification to achieve parallel performance. Doing as much as possible statically means that we do not pay this cost at runtime, where we’d have to claw back the overhead before gaining any performance through parallelisation. Modifying the binary dynamically means that we avoid dealing with the difficulties of static binary rewriting, such as handling jump tables and pc-relative addressing. It also allows us to easily specialise modified code for each thread that we generate (such as initialisation of induction variables or privatising variables to each thread’s local storage). Therefore, we take advantage of the benefits of each approach, with the time to perform sophisticated analysis offline, and the ability to specialise on execution.
The two faces of Janus are connected through our new architecture-independent interface that we call a rewrite schedule. The rewrite schedule is composed of a series of rewrite rules, each of which describes a single modification that should be made to the application. These may be simple alterations, such as changing the source register for a particular instruction, through to complicated transformations, like sending threads back to the thread pool after executing a parallelised loop. The following diagram from the paper shows this.
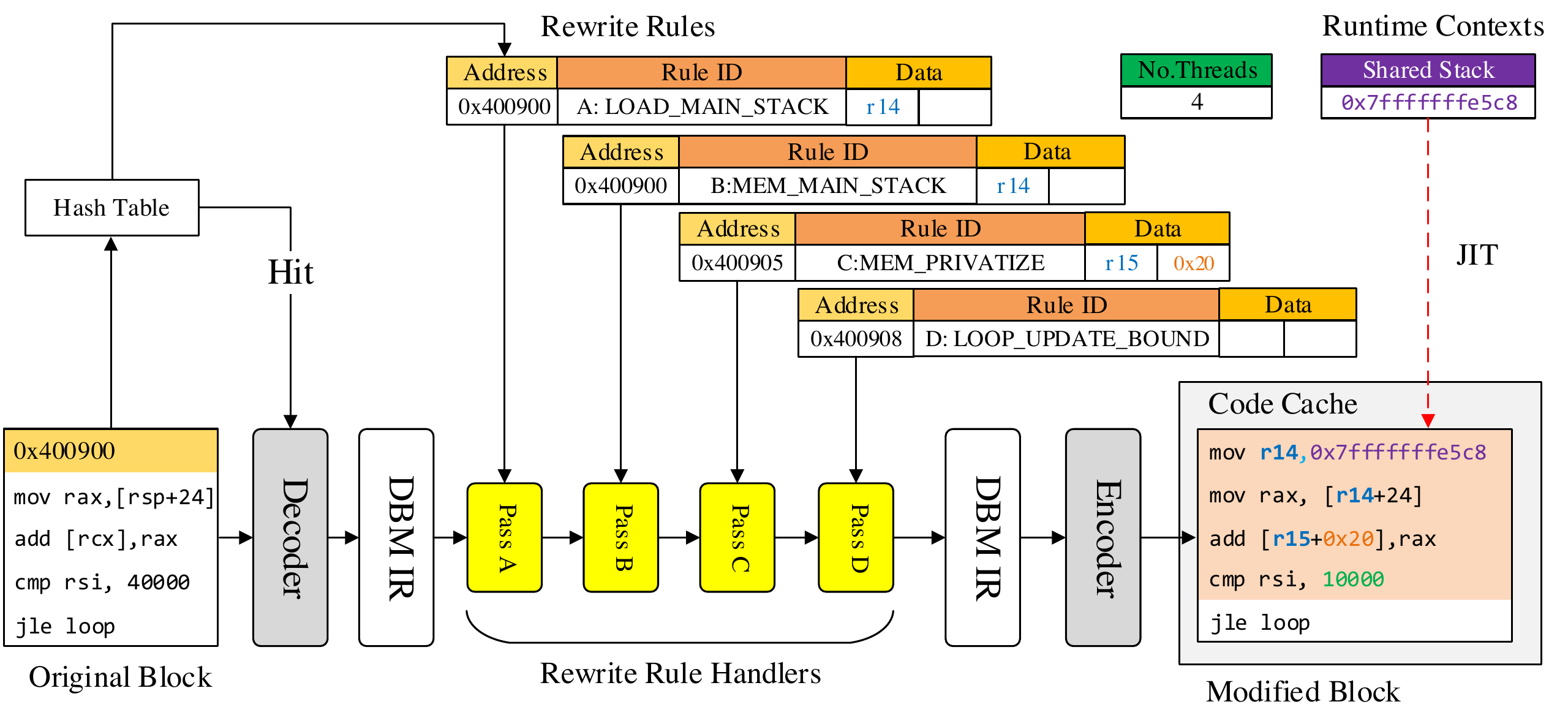
The diagram shows the original basic block of instructions on the bottom left, which is the granularity of instructions that we deal with (modify together) in Janus. The rewrite rules themselves are shown at the top in the middle. Each one has an address that it is associated with (that identifies a single instruction), an ID or action to take, and some data fields. When a basic block is decoded by DynamoRIO we take its address and look up in a hash table to determine whether any rewrite rules are associated with the block’s instructions. If so, then we invoke a handler for that rewrite rule according to its ID, which will modify the code at the instruction it is attached to. Multiple handlers can be associated with each address and they will be called in the order they appear in the rewrite schedule. In this example there are four rewrite rules associated with instructions in this basic block (two for the first instruction, one for the second and one for the third). Each of them modifies the code in turn. The resulting code is then encoded again by DynamoRIO and placed in its code cache. In this case the first two rewrite rules together alter the instruction to load a read-only variable from the program’s shared stack (instead of a thread-local stack), the third rule changes the location of the result of the instruction (here, to keep a thread-private version), and the fourth rule changes the number of iterations the loop executes, since each thread only runs a subset of them.
The second novelty in Janus is the ability to parallelise and execute loops correctly even when they contain code that is not available statically. Usually this comes from a library that is linked into the application at runtime, but it could be JIT-compiled code or something similar. In the case of a library, we could analyse any version that exists where Janus’ static analyser lives, but this wouldn’t give any guarantees about the same version being available when the program is executed. So we take a different approach in Janus by dealing with the problem at runtime through the provision of a speculation system. Our software transactional memory (STM) system gets enabled through a rewrite rule before any dynamically discovered code is executed. It buffers all values overwritten by stores and records all loaded addresses with their values to enable validation of the speculation later on. It has read/write buffering, lazy conflict detection and serial commits based on a global timestamp. Validation occurs after a thread finishes execution, when it must wait for all threads running earlier loop iterations to successfully validate first, and ensures that application memory contains the same values as would have been seen under sequential execution. Any errors cause transactions to roll back and try again.
This system works well for small sections of dynamically discovered code, especially those where we are reasonably confident that there will be very few writes to memory (if any). So why, you may well ask, don’t we use it more generally to speculate on loops that do have true cross-iteration data dependences, but we think they will only occur rarely? Well, unfortunately, the overheads of our STM are considerable and vastly swamp any benefits that its use might realise. That’s not because it is badly implemented, but because all STMs have high overheads that generally make them impractical to use for this kind of parallelisation. (If someone can provide me with a better STM for this purpose, I’d love to hear from you!) Let’s take a look at when speculation is useful then.
do i=1,nx ip1=mod(i,nx+1-ish)+ish ... mu=((gm-1.0d0)*(q(5,i,j,k)/ro-0.5d0*(u*u+v*v+w*w)))**0.75d0 ... enddo
 This code comes from the bwaves benchmark in SPEC CPU 2006. The compiler transforms
This code comes from the bwaves benchmark in SPEC CPU 2006. The compiler transforms ** into a call to pow(), a math library function for raising its first argument to the power of its second. Although we would not expect this function to read from or write to any non-local variables (i.e. global memory), we cannot be certain until we actually analyse the code. But since it is linked into the program dynamically we can’t do this, therefore, in the absence of speculation, this loop could not be parallelised. Instead, having the STM in Janus allows us to run different iterations at the same time, or out of order, safe in the knowledge that if this function does write to global memory, any dependence violations will be caught, reverted and respected. Although high overhead, when used sparingly this can be overcome and allow us to parallelise where we couldn’t otherwise.
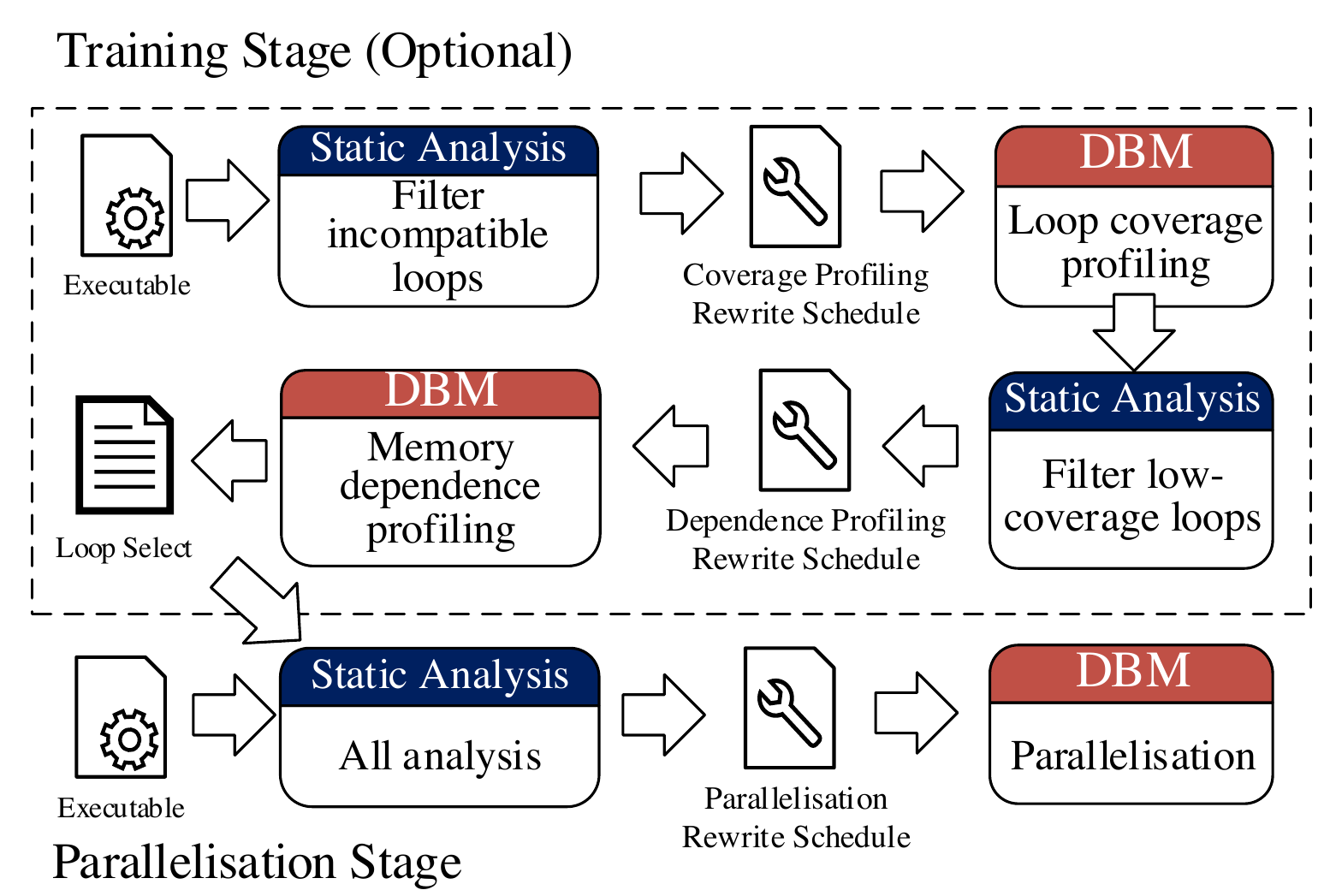
Janus works in several stages. Although it can simply perform a static analysis of an application binary and then immediately parallelise the DoAll loops at runtime, this does not unlock the largest amount of performance for most workloads (see the second graph below). Instead, an optional training stage can be performed where we perform loop-coverage profiling (to identify how much each loop contributes to overall program execution) and memory-dependence profiling (where we determine whether loops really do have cross-iteration data dependences or not when running with training inputs). The diagram on the right gives an overview of the different stages, where static analysis and execution take place, and the types of rewrite schedule that are produced each time.
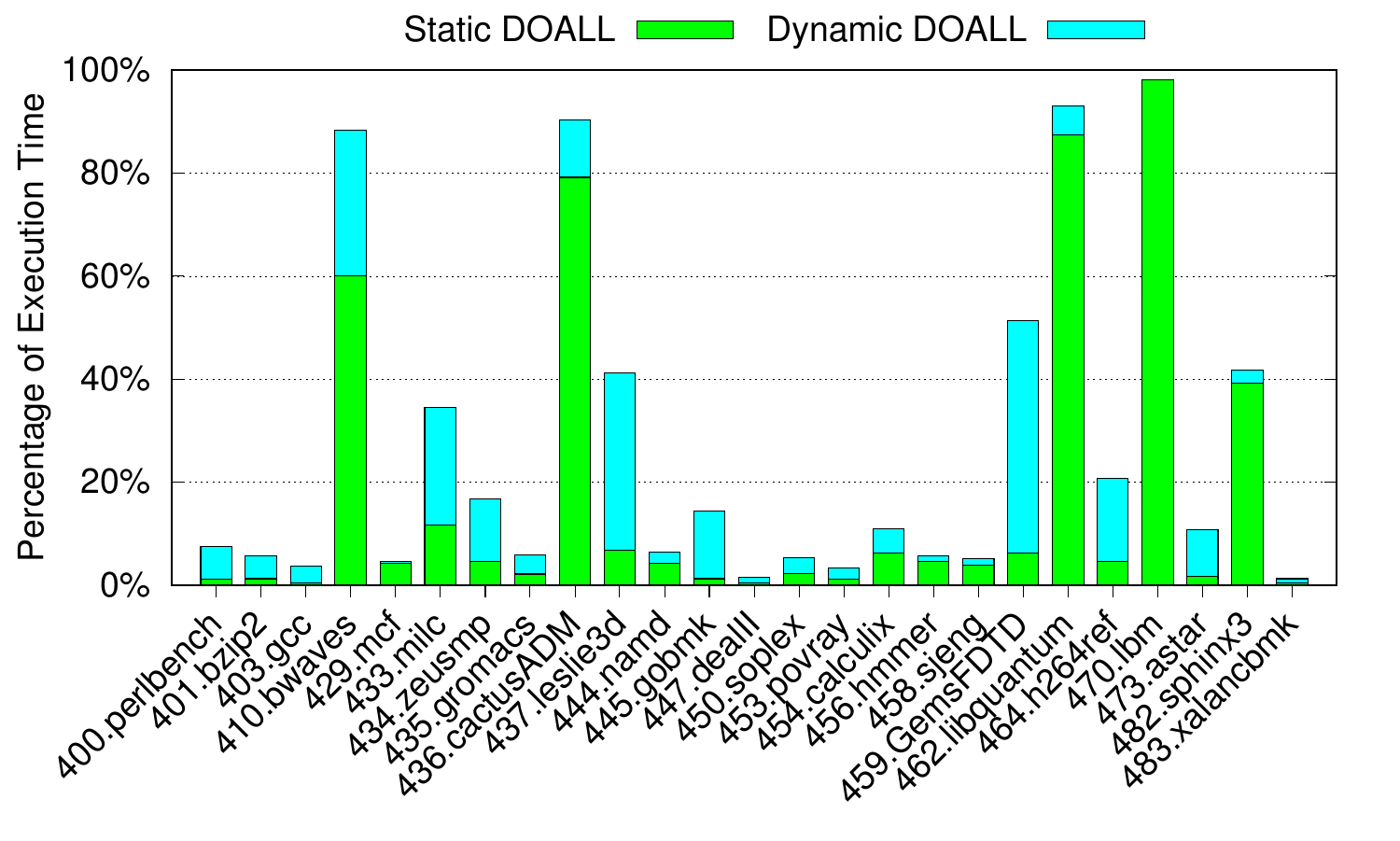 Now since Janus only parallelises DoAll loops (at the moment), it’s not applicable to all applications. This graph shows, for the SPEC CPU 2006 applications, the percentage of execution time spent in loops that we class as Static DoAll and Dynamic DoAll. The former are loops that Janus’ static analyser can determine are DoAll. The latter are those where the static analyser cannot prove that there are no cross-iteration data dependences, although it thinks that there is a good chance that there are none, and in actual fact it does not find any when the code is profiled. Only a handful of benchmarks spend a significant fraction of their execution time in these two kinds of loop, and they are the workloads that we consider further.
Now since Janus only parallelises DoAll loops (at the moment), it’s not applicable to all applications. This graph shows, for the SPEC CPU 2006 applications, the percentage of execution time spent in loops that we class as Static DoAll and Dynamic DoAll. The former are loops that Janus’ static analyser can determine are DoAll. The latter are those where the static analyser cannot prove that there are no cross-iteration data dependences, although it thinks that there is a good chance that there are none, and in actual fact it does not find any when the code is profiled. Only a handful of benchmarks spend a significant fraction of their execution time in these two kinds of loop, and they are the workloads that we consider further.
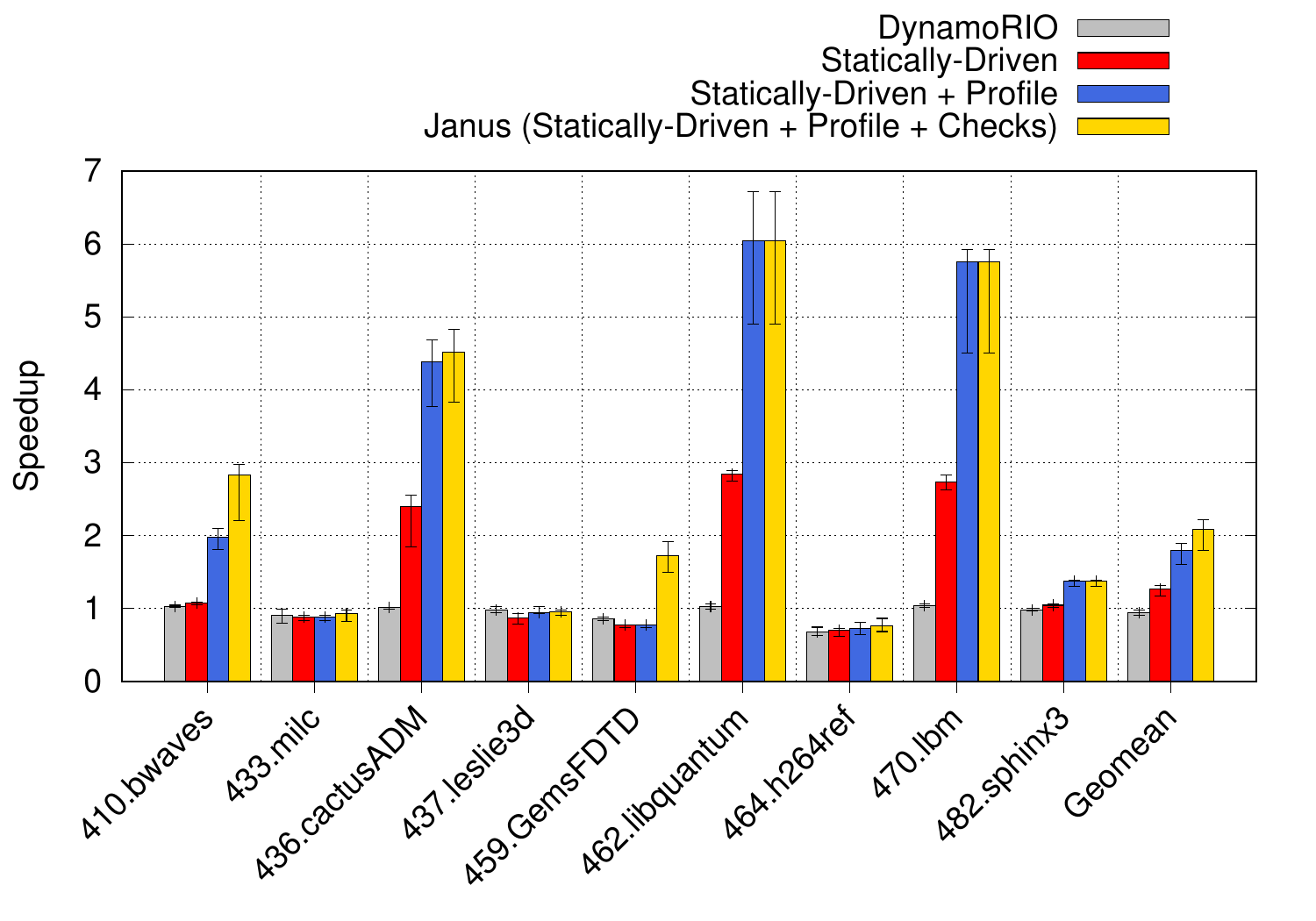 This graph shows the performance of Janus for those benchmarks that contain enough parallelism. It shows four bars representing the speedup using eight threads normalised to native single-threaded execution. The first bar (grey) shows the performance when running under DynamoRIO alone and is the overhead from the DBM that we must at least claw back through parallelisation to break even. For most applications this results in a minor slowdown, although for some, such as h246ref, it is considerable (0.68×). The next bar, in red, shows the performance when only using the static analyser to identify DoAll loops and parallelise all of them. For some benchmarks this is a positive approach, but for the majority it isn’t enough to realise speedups. The third bar shows what happens if we add in profile information, gathered through runs using training inputs (blue). The profile data is used to filter out loops that are DoAll, but are not profitable to parallelise (for example, they execute too few iterations and so the costs of setting them up to be run by multiple threads outweighs the benefits of parallelisation). This is enough for libquantum, lbm and sphinx3, and almost enough for cactusADM. Janus, however, is the final bar in yellow, that shows the full parallelisation approach with runtime checks to enable parallelisation of dynamic DoAll loops. The runtime checks ensure that there are no true cross-iteration data dependences and Janus only parallelises these loops at runtime if the checks pass (more information in the paper). This is essential for good performance from bwaves and GemsFDTD.
This graph shows the performance of Janus for those benchmarks that contain enough parallelism. It shows four bars representing the speedup using eight threads normalised to native single-threaded execution. The first bar (grey) shows the performance when running under DynamoRIO alone and is the overhead from the DBM that we must at least claw back through parallelisation to break even. For most applications this results in a minor slowdown, although for some, such as h246ref, it is considerable (0.68×). The next bar, in red, shows the performance when only using the static analyser to identify DoAll loops and parallelise all of them. For some benchmarks this is a positive approach, but for the majority it isn’t enough to realise speedups. The third bar shows what happens if we add in profile information, gathered through runs using training inputs (blue). The profile data is used to filter out loops that are DoAll, but are not profitable to parallelise (for example, they execute too few iterations and so the costs of setting them up to be run by multiple threads outweighs the benefits of parallelisation). This is enough for libquantum, lbm and sphinx3, and almost enough for cactusADM. Janus, however, is the final bar in yellow, that shows the full parallelisation approach with runtime checks to enable parallelisation of dynamic DoAll loops. The runtime checks ensure that there are no true cross-iteration data dependences and Janus only parallelises these loops at runtime if the checks pass (more information in the paper). This is essential for good performance from bwaves and GemsFDTD.
I could go on to show lots of other graphs, but they are all in our paper and so the best place to see them is there, with an explanation of each result and more in-depth information about how Janus works.
The great thing about Janus is that it is open source. We are releasing all our code to allow the community to benefit from our work and to improve it. As you may imagine, developing Janus has required a serious engineering commitment, and we don’t want others to have to go through the same pain as us! Please clone our repository on GitHub, improve the code, fix any bugs, add in new features, and ask us to merge in your changes. We’d love to build a community around Janus and revive research into binary modification techniques. You can download Janus from https://github.com/JanusDBM/Janus.
