
Submitted by Timothy Jones on Thu, 23/02/2017 - 09:39
I’ve always considered software prefetching to be something of a black art. There have been times in the past when I’ve looked at my code, noticed a load is causing problems and tried inserting one or more software prefetches to alleviate the issue. Mostly this hasn’t worked, although I’ve never been sure why. In fact, even when it has worked I haven’t been totally sure why it has, usually because it’s involved a lot of trial and error in trying out different options before I hit on improved performance.
Now it turns out that most of the time I was probably trying to prefetch the wrong things. Trying to prefetch linked data structures, which are those that involve pointer chasing (like a linked list), is not likely to work because there is no memory-level parallelism available. After all, the whole point of prefetching is to bring data into the L1 cache at the same time as performing useful work, so that the data is available at the point it is needed. Without memory-level parallelism, no useful work can be performed whilst waiting for each prefetch and they become useless. On the other hand, for simple access patterns, such as traversing an array, there is no point trying to perform prefetching in software because the hardware prefetcher inside each core can already identify these use cases and do a great job in bringing data into the cache just before it is needed.
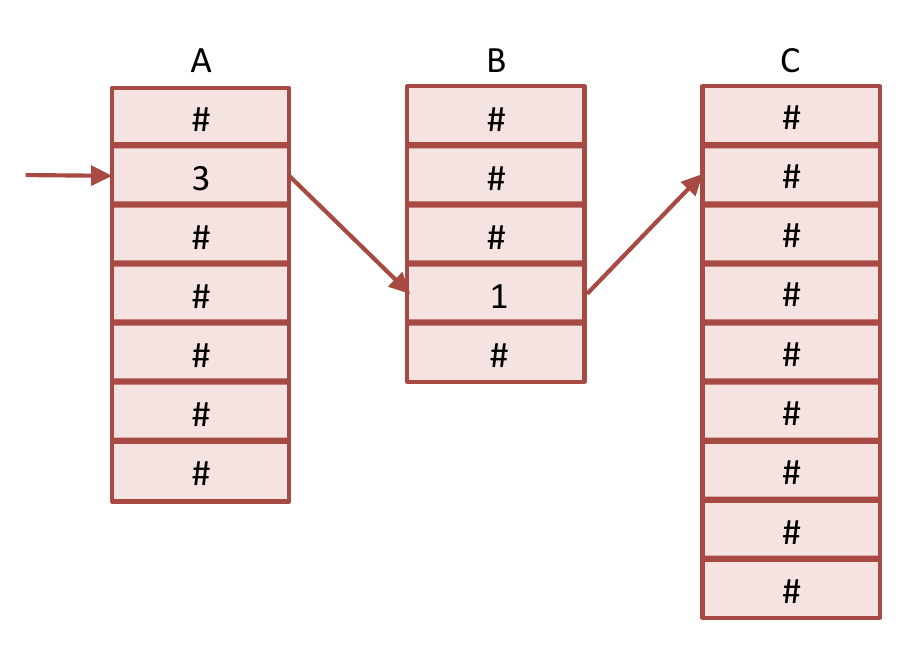 All that being said, there is one type of access pattern that software prefetches can help with considerably. This is when you access one array through one or more other arrays. In other words, you look up in one array and use the obtained data as an index into a second array, possibly repeating this several times. An example with three arrays is shown here, where the
All that being said, there is one type of access pattern that software prefetches can help with considerably. This is when you access one array through one or more other arrays. In other words, you look up in one array and use the obtained data as an index into a second array, possibly repeating this several times. An example with three arrays is shown here, where the C array is accessed through the B array, which is accessed through the A array (or C[B[A[i]]]). This is known as a memory-indirect access pattern. When traversing arrays in this manner there is both an abundance of memory-level parallelism and no discernible pattern that the hardware prefetcher can identify. The former comes from the starting array, which is usually accessed sequentially, each element after its predecessor, perhaps in a for loop with an induction variable that increases by 1 each time. This provides plenty of memory-level parallelism because it is easy to look ahead in that array at a fixed offset from the current computation’s index. The latter comes about because the index into each subsequent array is entirely data dependent and the hardware prefetcher has no way of knowing that you are using the contents of one array to index into another (although see our ICS 2016 paper and blog post for a new, specialised prefetcher that can achieve this for graphs).
However, even though we can identify situations that software prefetching can help, it is not always easy to add in software prefetch instructions to achieve optimal performance. This is the subject of my CGO paper that was published earlier this month and is joint work with my PhD student, Sam Ainsworth. The graph shown below comes from the paper and corresponds to this code from the IS benchmark in the NAS workloads:
for (i=0; i<NUM_KEYS; i++) {
// The intuitive case, but also
// required for optimal performance.
SWPF(key_buff1[key_buff2[i + offset]]);
// Required for optimal performance.
SWPF(key_buff2[i + offset*2]);
key_buff1[key_buff2[i]]++;
}
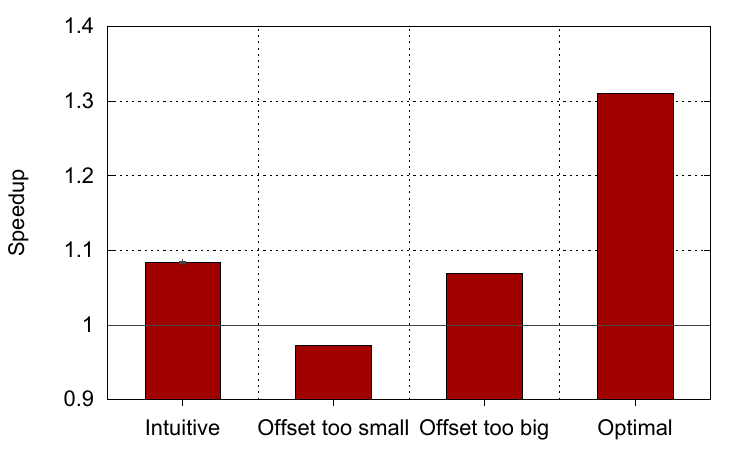 In essence, one array (
In essence, one array (key_buff2) is accessed sequentially and its data is used as an index into a second array (key_buff1). The naïve way to improve this workload is to add a prefetch for the data in the second array, which of course means accessing the first array too at a certain offset from the current index. This is the first software prefetch in the code and does give speed-up, as shown by the first bar in the graph, whose data was collected from an Intel Haswell core. However optimal speed-up is only achieved when adding in another prefetch for the data in the first array at double this offset, to allow time for this data to arrive into the L1 cache so it is there when the other prefetch needs it. Even then it is not totally straightforward to obtain good performance though. Choosing an offset that is too small means that data does not arrive in the cache before it is required, and a fair few extra instructions are executed, so performance is worse than doing nothing. Choosing an offset that is too big means that data arrives too early and may be kicked out of the cache before it is used by other prefetches. At least this time performance increases, but it’s suboptimal and lower than just having the first prefetch alone. In fact, the best performance gain of 30% can only be achieved by including both prefetches and setting the offset correctly (there is no single best value for the offset, it just has to be within a range of good values).
In the paper we create a compiler pass that will automatically identify opportunities to insert prefetches where we find these memory-indirect accesses. The pass is fully automated and works by identifying loads within loops that meet certain conditions. One of these is that there must be an induction variable within the transitive closure of the source operand (which, for a load, is the operand that calculates the address to load from). This means we search backwards through the data dependence graph, starting at the load, until we find this induction variable. When we have identified loads that need to be prefetched then we duplicate all of the necessary computation to calculate the address and insert the software prefetch instructions. We also have to add code around any loads that are part of this address computation to prevent them from causing errors at runtime if they calculate an invalid address, for example running beyond the end of an array. There are more details in the paper including information about how we schedule the prefetches so that data is available immediately before being used.
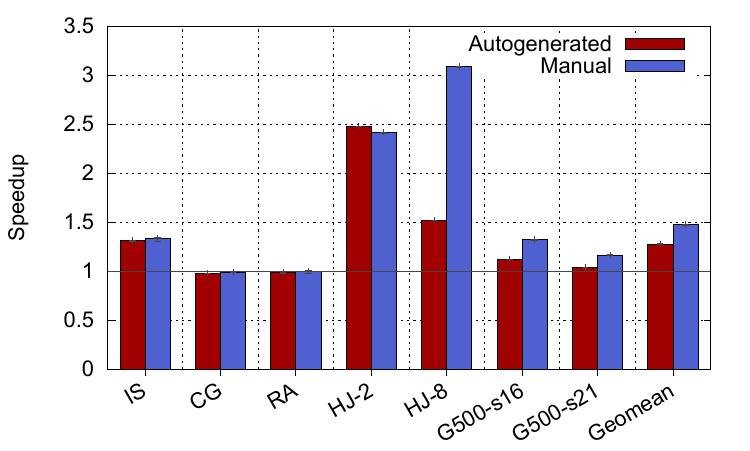 Here are the performance results for two of the systems we evaluated at opposite ends of the spectrum. The first is an Intel Haswell processor, which is a very high performance out-of-order superscalar core that is capable of extracting a large amount of both instruction-level and memory-level parallelism (ILP and MLP). The other system is a first generation Intel Xeon Phi, which is a very simple in-order core that basically stalls on each load that misses in the cache. There are two bars in the Haswell graph, corresponding to the performance of our benchmarks using our automatically-generated software prefetch instructions inserted by the compiler and the best manual insertion of software prefetch instructions that we could achieve. Minor differences in the performance of the two schemes, for example in IS and HJ-2, are simply down to slightly different code generation in the compiler backend. As the graph shows, in two benchmarks there is over 2x performance available and in the best case our auto-generated pass enables speed-ups of 2.5x. Across all benchmarks the average performance is 30% higher than the baseline when using our compiler pass. There are more details in the paper about the different characteristics of the workloads. However, I’d take a 30% improvement any day (let alone 150%!) just from enabling a compiler flag, especially on a high-performance core.
Here are the performance results for two of the systems we evaluated at opposite ends of the spectrum. The first is an Intel Haswell processor, which is a very high performance out-of-order superscalar core that is capable of extracting a large amount of both instruction-level and memory-level parallelism (ILP and MLP). The other system is a first generation Intel Xeon Phi, which is a very simple in-order core that basically stalls on each load that misses in the cache. There are two bars in the Haswell graph, corresponding to the performance of our benchmarks using our automatically-generated software prefetch instructions inserted by the compiler and the best manual insertion of software prefetch instructions that we could achieve. Minor differences in the performance of the two schemes, for example in IS and HJ-2, are simply down to slightly different code generation in the compiler backend. As the graph shows, in two benchmarks there is over 2x performance available and in the best case our auto-generated pass enables speed-ups of 2.5x. Across all benchmarks the average performance is 30% higher than the baseline when using our compiler pass. There are more details in the paper about the different characteristics of the workloads. However, I’d take a 30% improvement any day (let alone 150%!) just from enabling a compiler flag, especially on a high-performance core.
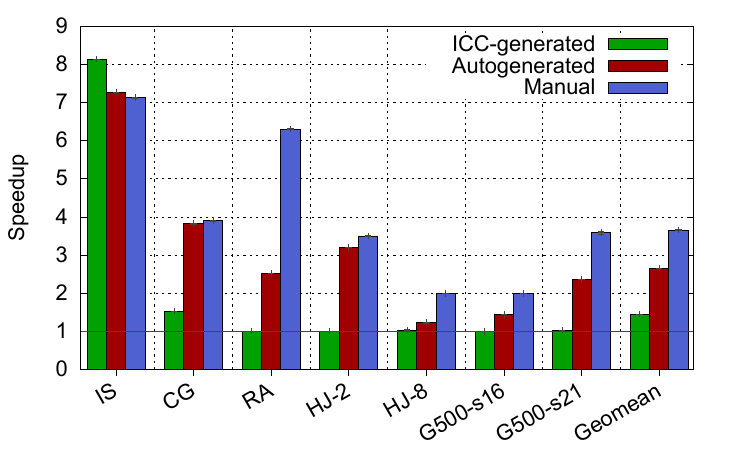 Turning to the Xeon Phi results, there is a third bar in the graph. This corresponds to the performance of the benchmarks when compiled with Intel’s own compiler, ICC, which has support for generating software prefetches for some indirect access patterns. However, only IS achieves significant speed-up using ICC. Our compiler pass also correctly identifies the best loads to prefetch and inserts the instructions, but ICC hoists some of the loop-invariant code above the loop, which is an optimisation we didn’t enable in our prototype. On the other hand, our automated compiler pass can achieve significant speed-ups for almost all benchmarks, with an average of 2.7x. The Xeon Phi is a simple in-order microarchitecture, so you’d expect better results here from extracting the memory-level parallelism compared to Haswell, because the Phi is lacking the hardware support that Haswell has for extracting some of this.
Turning to the Xeon Phi results, there is a third bar in the graph. This corresponds to the performance of the benchmarks when compiled with Intel’s own compiler, ICC, which has support for generating software prefetches for some indirect access patterns. However, only IS achieves significant speed-up using ICC. Our compiler pass also correctly identifies the best loads to prefetch and inserts the instructions, but ICC hoists some of the loop-invariant code above the loop, which is an optimisation we didn’t enable in our prototype. On the other hand, our automated compiler pass can achieve significant speed-ups for almost all benchmarks, with an average of 2.7x. The Xeon Phi is a simple in-order microarchitecture, so you’d expect better results here from extracting the memory-level parallelism compared to Haswell, because the Phi is lacking the hardware support that Haswell has for extracting some of this.
One thing we haven’t explored in the paper is the point at which inserting software prefetches adds more overhead than can be overcome by taking advantage of memory-level parallelism. The graph below explores this using a modified version of IS from the NAS benchmark suite (available on my group’s data page or direct). The main work from this application is shown at the start of this post. To test the effects of prefetching we modified it to increase the number of arrays used for indirection, meaning that instead of two array accesses, up to ten have to be performed. The graph shows increasing numbers of arrays on the x-axis and increasing numbers of prefetches for each bar in the group (i.e. increasing the number of arrays that are prefetched). Also shown for comparison is the auto-generated prefetching, which prefetches for all arrays. The run times are normalised to the same version of the workload without prefetching.
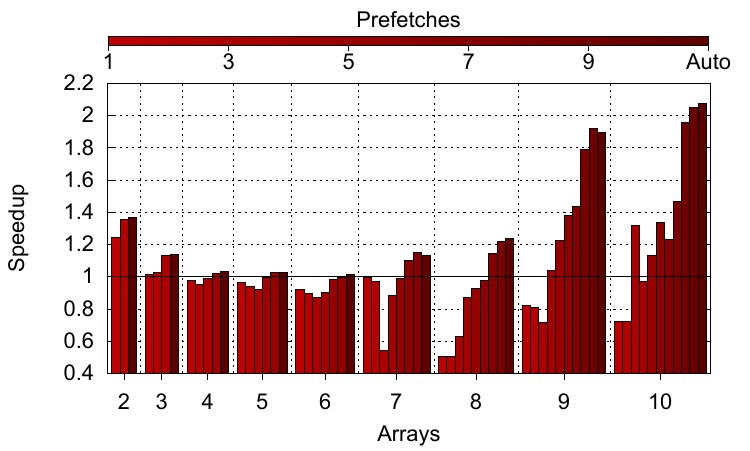 What’s obvious is that for more than three arrays, only performing a few prefetches is a bad idea. For eight arrays, even just adding a single prefetch instruction causes severe slow-downs (basically halving performance). For others, most noticeably with seven arrays, performance drops off with increasing prefetches, but then recovers and eventually starts to give speed-ups. In fact, prefetching for all arrays is always beneficial. While we can’t be certain what is happening here, it appears that with few prefetches the benefit obtained is minimal and this is offset by increasing the number of instructions within each loop iteration, which fill up the reorder buffer and prevent the core from extracting memory-level parallelism by itself. With eight arrays, the code for one prefetch probably increases code just enough to prevent two iterations of the loop from being within the core’s instruction window at the same time. Prefetching everything means that the trade-off is reversed and the extra benefits from exploiting MLP outweigh the extra instructions required. Bearing in mind that the amount of code added to generate the prefetches is O(n2), where n is the number of loads required in the original code, it is surprising that we haven’t seen the effects of many extra instructions causing slowdowns for high prefetch counts. This probably goes to show how large the gap is between processor and memory performance, since the core is able to execute all these instructions and the overheads are hidden behind the increase in performance through the cache hits they enable.
What’s obvious is that for more than three arrays, only performing a few prefetches is a bad idea. For eight arrays, even just adding a single prefetch instruction causes severe slow-downs (basically halving performance). For others, most noticeably with seven arrays, performance drops off with increasing prefetches, but then recovers and eventually starts to give speed-ups. In fact, prefetching for all arrays is always beneficial. While we can’t be certain what is happening here, it appears that with few prefetches the benefit obtained is minimal and this is offset by increasing the number of instructions within each loop iteration, which fill up the reorder buffer and prevent the core from extracting memory-level parallelism by itself. With eight arrays, the code for one prefetch probably increases code just enough to prevent two iterations of the loop from being within the core’s instruction window at the same time. Prefetching everything means that the trade-off is reversed and the extra benefits from exploiting MLP outweigh the extra instructions required. Bearing in mind that the amount of code added to generate the prefetches is O(n2), where n is the number of loads required in the original code, it is surprising that we haven’t seen the effects of many extra instructions causing slowdowns for high prefetch counts. This probably goes to show how large the gap is between processor and memory performance, since the core is able to execute all these instructions and the overheads are hidden behind the increase in performance through the cache hits they enable.
So there we have it. Software prefetch for indirect memory accesses. Automatically. It works and produces great speed-ups with no more black magic. Feel free to try it out yourself using our github repository and let me know how you get on.
