
Submitted by Timothy Jones on Wed, 27/06/2018 - 09:58
Soft, or transient, errors are faults that occur seemingly at random, causing bits to flip within an integrated circuit. This is especially important in memory cells, and I remember very clearly reading a blog post from James Hamilton several years ago now, where he talked about the need for ECC on DRAM in servers and discussed some (what was then) recent academic work in the subject. ECC is a great way to protect memory, being high performance with low power and area overheads, given its ability to detect multiple errors and correct some too. However, beyond the memory hierarchy, techniques for error detection and recovery are little used due to the difficulties in protecting logic cheaply.
One area where error detection is mandatory is in safety-critical systems, where the price of being wrong far outweighs the additional costs of providing some sort of redundancy to, at least, detect errors. The automotive sector, for example, has strict safety standards, with ASIL C and D, the highest integrity levels for a product, requiring redundancy for certification. Microprocessor implementations tend to realise this through the use of dual-core lockstep, a system whereby each core is replicated, identical software run on each (usually at a slight offset in time to avoid correlated errors) and additional logic provided to check each computation as it occurs. Recovery generally involves resetting the system, which is acceptable when there is little or no state to get corrupted. However, dual-core lockstep is costly in terms of both silicon area and power. With a desire to use more high-performance cores in these real-time systems, this latter cost becomes too much: out-of-order superscalar processors are incredibly power inefficient.
Of course, there has been significant work in academia on alternatives to dual-core lockstep, in software as well as hardware. Redundant multi-threading, in particular, has seen considerable interest, where a secondary thread executes the same instructions as the main program. Although this thread can be run on the same core as the original, avoiding the additional area costs, performance takes a big hit and energy overheads remain high.
The work we publish at DSN this week takes a different approach. Using the principle of strong induction we can parallelise the error-checking code. This allows us to run on a set of very small and power-efficient cores, decoupled from the main high-performance core, but connected through a hardware queue that logs loads and stores committed by the main program. An overview of our architecture is shown below.
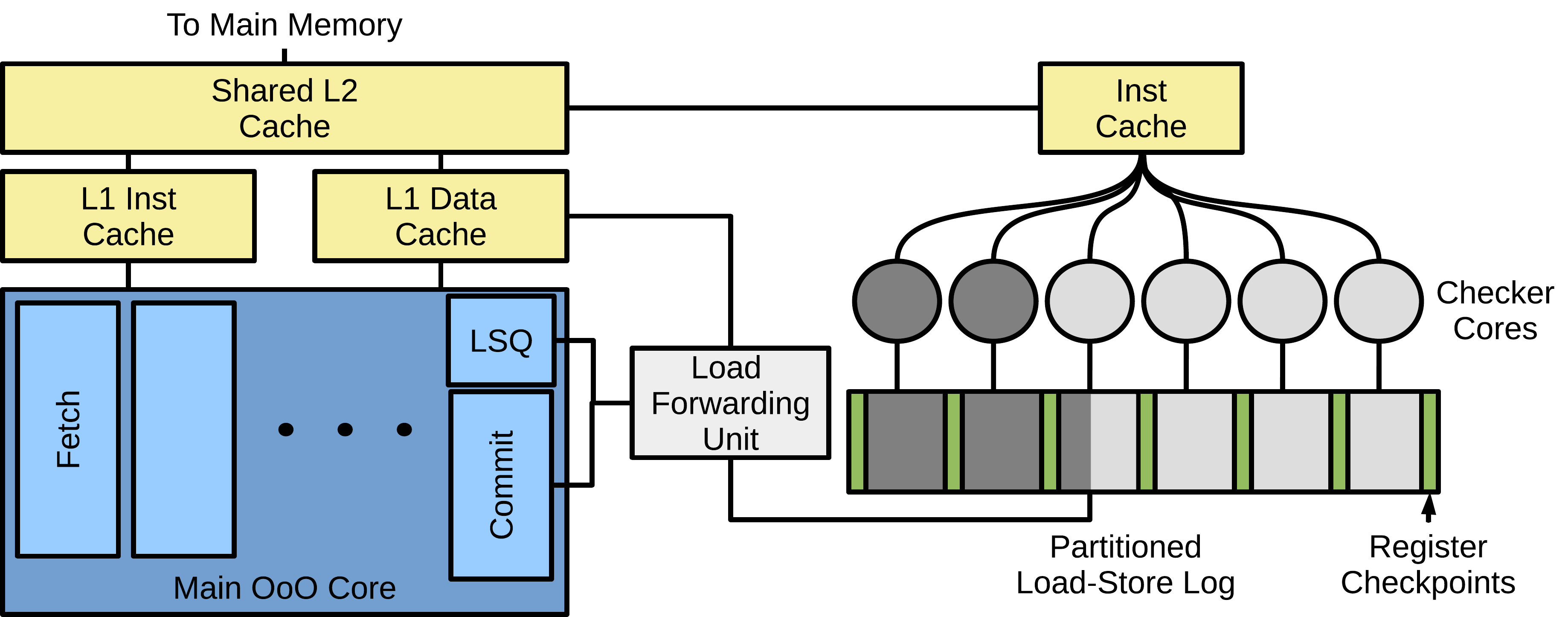
Our system works like this. Periodically we take a checkpoint of the main core’s state; basically copying all architectural registers to the load-store log. Execution then continues on the main core, but as we do so, all load and store addresses and data are logged. For loads, addresses that are sent to the cache are placed into a buffer (the load forwarding unit) and data returned by the cache is too. It’s important to note that we assume ECC on the L1 cache and that data is sent to the load forwarding buffer through a separate channel to the one used by the core. This means that there is true replication of the data and at no point can an error be propagated to both the main core and the buffer. Addresses and data leave the buffer when their corresponding loads are committed within the main core, meaning that mis-speculated loads do not pollute the load-store log; everything in this log corresponds to committed instructions in program order. Stores, in contrast, write addresses and data directly into the load-store log since they only leave the core upon commit. Once a segment of the load-store log has been filled (or on a timeout) we checkpoint the main core once again.
At this point we have a segment of the load-store log that has captured all loaded and stored values and addresses, as well as the main core’s state both at the start and end of the segment. We can now proceed to check that these values are correct. This is accomplished through the use of a checker core, one of our small and power-efficient cores. It initialises its state using the checkpoint at the start of a load-store log segment, then runs exactly the same sequence of instructions as the main core did. When it reaches a load instruction, it checks the address it is due to load from is the same as the main core used, by comparing the address in the load-store log with its own. It then loads the data associated with that load-store log entry, instead of loading from the cache. In this way, it obtains the same memory data as the main core did. Upon a store, it checks the address stored to and the data stored, in exactly the same way as for load addresses. These checker cores never do stores of their own, they just check the addresses and data that the main core stored. Finally, once all instructions have been executed, it checks all checkpoint data is the same as that stored in the load-store log at the end of the segment. If there is a mismatch at any point (with load addresses, store addresses or data, or with the segment-end checkpoint) then the checker core triggers an exception to flag up the error. The principle of strong induction gives us the opportunity to exploit parallelism in the error checking, because multiple load-store log segments can be checked in parallel by different checker cores: each checks the memory accesses within a segment and the final checkpoint, knowing that the predecessor core will check the starting checkpoint. This means each core temporarily assumes that all previous checkpoints were correct while checking its own load-store log segment; merging all of these checks together gains full-program correctness.
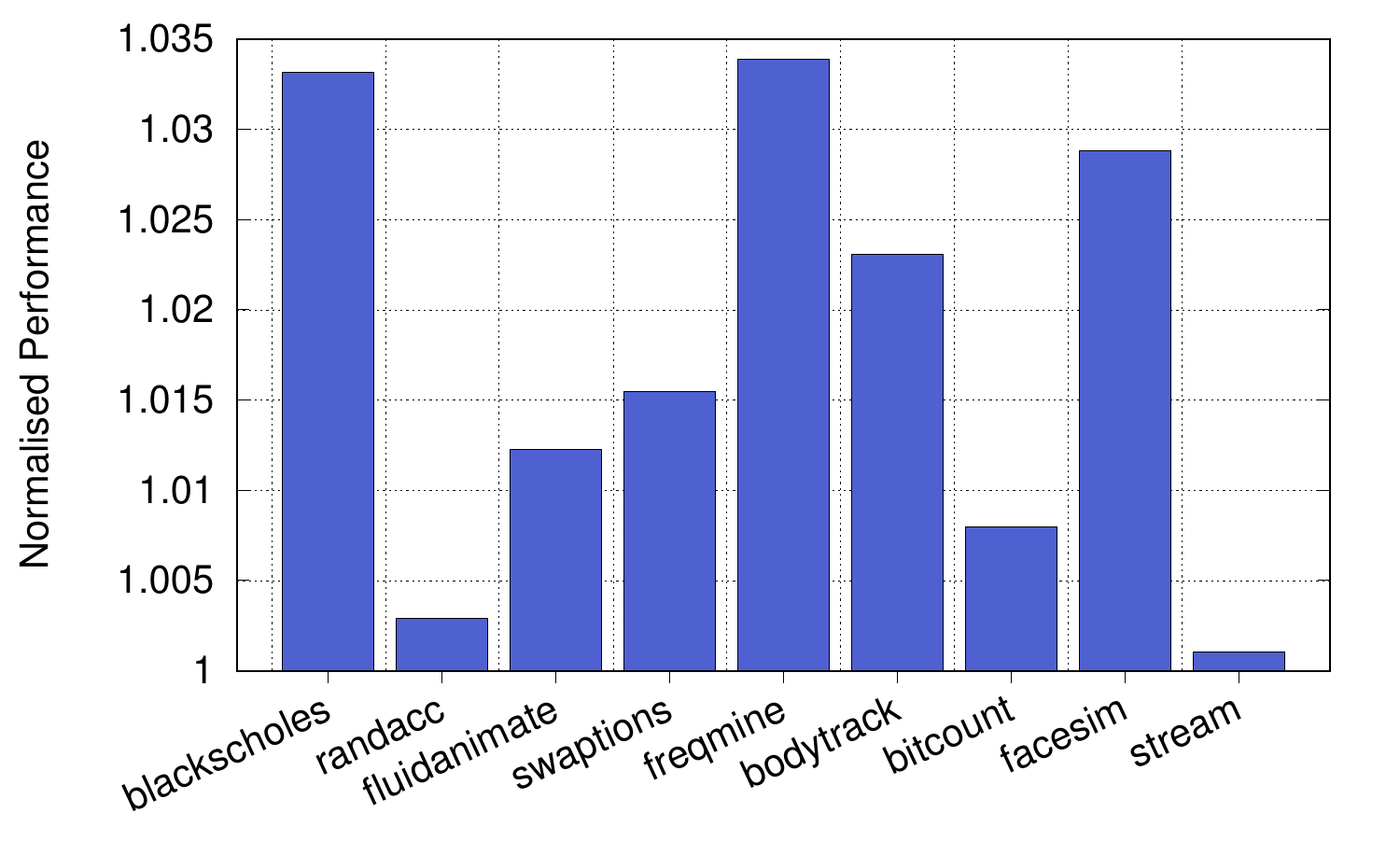 The checkpoint saving and there sometimes not being a checker core available means that we incur a small slowdown when using our error checking architecture. The graph on the left shows that this is tiny. We picked a range of multithreaded applications from Parsec, along with bitcount from MiBench (or cbench), which is almost purely compute bound, and random access and stream from the HPCC Challenge benchmark suite, which are almost entirely memory bound (both irregular and regular memory accesses). We used an array of 12 in-order checker cores, each running at 1GHz and checking a high-performance 3-wide out-of-order superscalar processor running at 3.2GHz and with a load-store log segment size of 3KiB. The highest overhead was less than 3.5% for blackscholes and freqmine. The paper also shows results varying the size of the load-store log segment size, varying the checker cores’ frequency and time between a store committing and the error being detected with varying parameters. This latter value is important, because it affects how quickly an error can be dealt with and an action started (or cancelled) if required. For all our applications, 99.9% of errors with loads and stores are caught within 5μs.
The checkpoint saving and there sometimes not being a checker core available means that we incur a small slowdown when using our error checking architecture. The graph on the left shows that this is tiny. We picked a range of multithreaded applications from Parsec, along with bitcount from MiBench (or cbench), which is almost purely compute bound, and random access and stream from the HPCC Challenge benchmark suite, which are almost entirely memory bound (both irregular and regular memory accesses). We used an array of 12 in-order checker cores, each running at 1GHz and checking a high-performance 3-wide out-of-order superscalar processor running at 3.2GHz and with a load-store log segment size of 3KiB. The highest overhead was less than 3.5% for blackscholes and freqmine. The paper also shows results varying the size of the load-store log segment size, varying the checker cores’ frequency and time between a store committing and the error being detected with varying parameters. This latter value is important, because it affects how quickly an error can be dealt with and an action started (or cancelled) if required. For all our applications, 99.9% of errors with loads and stores are caught within 5μs.
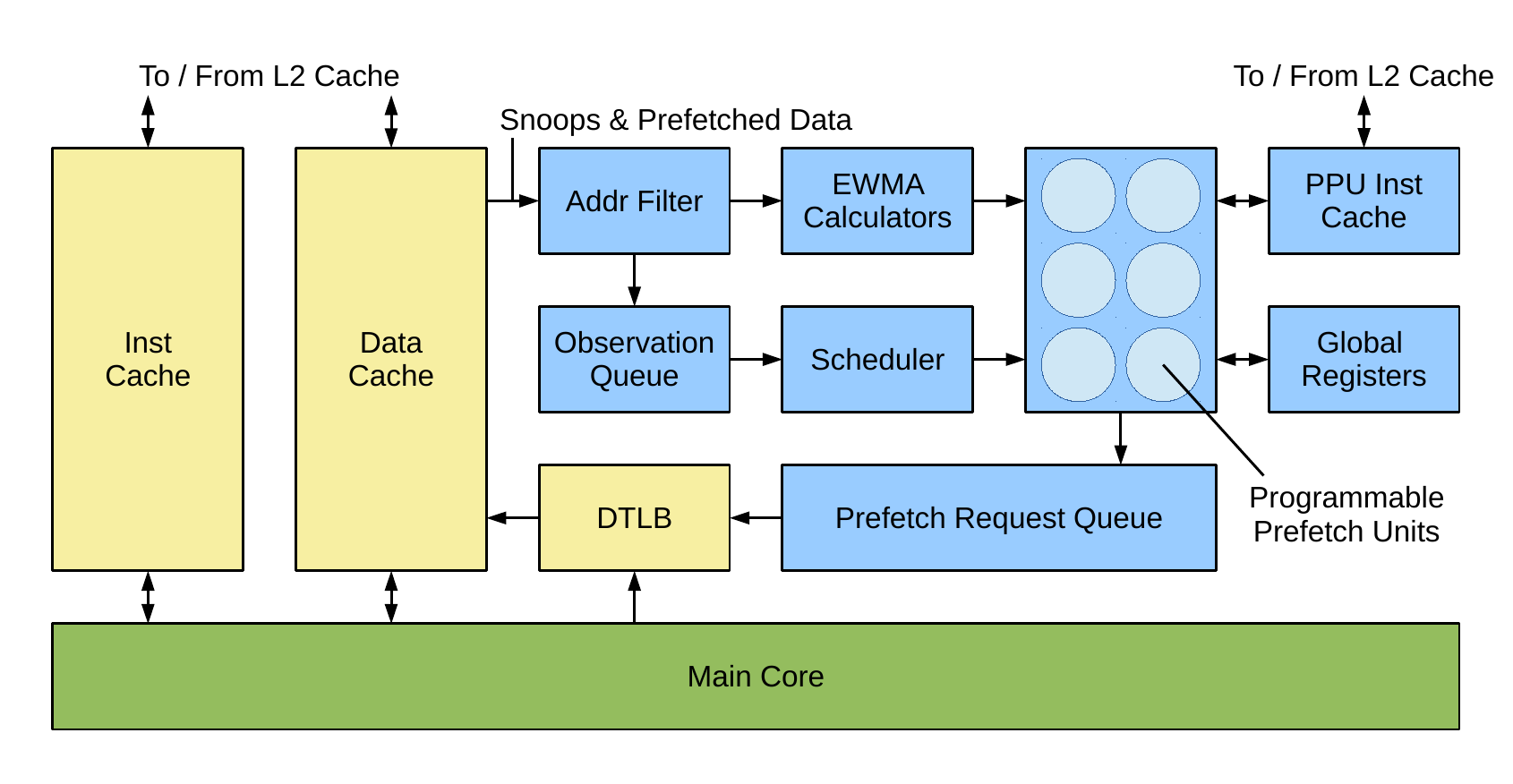 Now if you’ve read some of my other blog posts, you may see a similarity between this architecture and our programmable prefetch units, a reminder of which is shown on the right. We believe that there is significant value in having an array of small cores attached to a high-performance and high-power main core, providing a wide range of helper functions that exploit the parallelism inherent in their use cases. We have at least two more examples of when this type of architecture is beneficial which I’ll write about when the schemes are published. For now though, you can read our error-detection paper here and reflect on the fact that by exploiting parallelism we can give almost the same guarantees as dual-core lockstep but with an area overhead of just 24%.
Now if you’ve read some of my other blog posts, you may see a similarity between this architecture and our programmable prefetch units, a reminder of which is shown on the right. We believe that there is significant value in having an array of small cores attached to a high-performance and high-power main core, providing a wide range of helper functions that exploit the parallelism inherent in their use cases. We have at least two more examples of when this type of architecture is beneficial which I’ll write about when the schemes are published. For now though, you can read our error-detection paper here and reflect on the fact that by exploiting parallelism we can give almost the same guarantees as dual-core lockstep but with an area overhead of just 24%.
