
Submitted by Timothy Jones on Wed, 28/03/2018 - 13:27
Over the last few years my PhD student, Sam Ainsworth, and I have been looking into data prefetching, especially for applications containing irregular memory accesses. We published a paper in ICS 2016 about a specialised hardware prefetcher that optimises breadth-first traversals on graphs in the commonly-used compressed sparse-row format, which I previously blogged about. We also published a paper at CGO on automatic software-prefetch generation, more generally for indirect memory accesses (blog post). At ASPLOS this year, we marry the two ideas together and generalise even further, creating a programmable prefetcher, using an event-driven programming model, that is capable of fetching in data for many types of memory access, complete with a compiler pass to automatically generate the prefetching code when directed by the developer. The paper is available from my website now.
I’m going to dive right in with the details here because I’ve motivated the need for more intelligent prefetching in previous posts. In this one I want to describe the architecture and our programming model, and give some intuition of the relative merits of the three different ways of programming it.
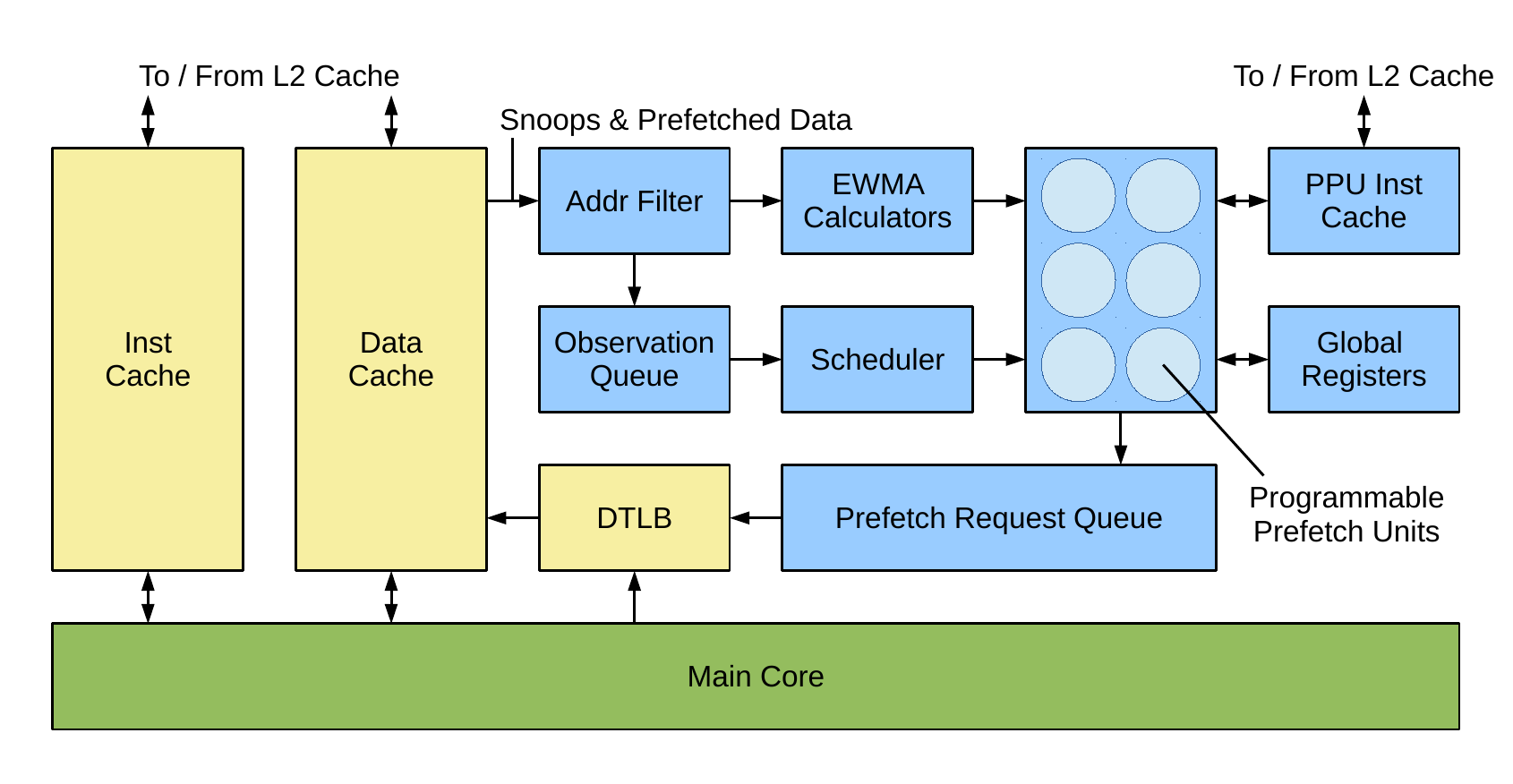 An overview of the prefetcher’s architecture is shown above. It contains many of the same features as our graph prefetcher, in that it has an address filter, EWMA calculators and a prefetch request queue, whilst also interfacing with the main core’s memory hierarchy in the same manner—it sits beside the L1 data cache, can snoop operations that occur there, prefetches into the L1, and also operates on virtual addresses, with a connection to the level 1 data TLB.
An overview of the prefetcher’s architecture is shown above. It contains many of the same features as our graph prefetcher, in that it has an address filter, EWMA calculators and a prefetch request queue, whilst also interfacing with the main core’s memory hierarchy in the same manner—it sits beside the L1 data cache, can snoop operations that occur there, prefetches into the L1, and also operates on virtual addresses, with a connection to the level 1 data TLB.
Entry to the prefetcher is through the address filter, which snoops L1 data cache operations, in particular load requests, loaded data arriving (if the load missed) and prefetched data arriving. Based on the address being loaded or prefetched, the events are filtered (we configure the prefetcher to know about the bounds of arrays we want to prefetch from, as well as being able to tag specific addresses to allow their events to pass through the filter). From here they move into the observation queue, waiting to be handled, where they are combined with some event-specific code that the programmer has written (or the compiler has generated) to deal with the event. We call these prefetch kernels.
The main part of the prefetcher is an array of very small cores, that we term programmable prefetch units (PPUs). These cores really are tiny—microcontroller sized, which can be implemented in just 12,000 gates—and they run the code that handles each observation, analysing the event and likely generating one or more prefetches as a result. The scheduler is therefore responsible for removing observations from the queue once a PPU becomes available and starting execution of the prefetch kernel. Generated prefetches are placed into the prefetch request queue and from here propagate into the memory hierarchy as and when the L1 data cache has spare cycles to deal with them.
The novelty in our technique is the provision of programmable prefetch units, the ability to program them using prefetch kernels and the event-driven programming model. Together they provide a sophisticated prefetching system that is capable of dealing with a wide range of workloads and memory access patterns, reacting in a timely manner to bring data into the L1 cache with high accuracy.
Use of an event-driven programming model is both key to performance and energy efficiency, but also a natural choice for the situation in which we deploy these programmable units. It allows us to leave the prefetch units turned off when there is no work to do, but react quickly when a new observation arrives. There is no global state required across prefetches (beyond that which we provide as configuration to the whole prefetcher) and so any PPU can handle any observation, which also lends itself to this model of computation. (Note that the PPUs have no direct connection to memory; all data, such as the cache line involved or tag, comes with the observation, or is configured in advance and held in the global registers.) The event-driven model allows us to fit naturally to the highly parallel nature of prefetching, whereby lots of prefetches can be in-flight at once, targeting different parts of the data structure and different elements that will be used across a number of future iterations of the loop running on the main compute core. Since we have this massive parallelism, and the PPUs do not perform much compute when reacting to each observation, it makes sense to provide a large number of small, low-power cores with an aggregate performance sufficient to keep up with the frequency of the main core. This setup is orders of magnitude more efficient compared to using a high performance core to do the prefetching.
![]()
The programming model requires the developer to create the prefetch kernels that will run on each event. We provide three methods to achieve this, ranging in their ease of use and flexibility. At one extreme, the programmer can simply add a #pragma prefetch directive to the top of the loop that he or she wants to add prefetching to. This is simple, but can only pick up certain access patterns, essentially those based on a stride-indirect access to an array. At the other extreme, the developer can write their own prefetch kernels—they are just functions written in the same programming language as the rest of the application. These give maximum flexibility to prefetch many kinds of memory access pattern but can be fiddly to get right (e.g. to choose the right offsets or the best structures to prefetch). A compromise is software-prefetch conversion, which takes software-prefetch directives within the application and converts them to prefetch kernels instead. This is especially useful for applications that already have software prefetches inserted. Here you combine ease of use with the ability to prefetch any access pattern that software prefetches can (for example, it is not possible to express loops within software prefetches). The following are some examples of how to use each method.
int sum=0;
#pragma prefetch
for (int i=0; i<N; ++i) {
sum += B[A[i]];
}With pragma prefetching, the directive simply needs to be added to the top of the loop. In this example two prefetch kernels would be created. The first would get triggered on seeing a load from the A array at index i and would create a prefetch to A at an offset from i (i.e. A[i+offset]). The second would get triggered on seeing data from a prefetch to A arrive in the cache, and would create a prefetch to B using that data (i.e. B[A[i+offset]]).
int sum=0;
for (int i=0; i<N; ++i) {
SWPF(A[i + 2*offset]);
// Assume B[A[i]] and B[A[i]+1] share a cache line
SWPF(B[A[i + offset]]);
sum += B[func(i) ? A[i] : A[i]+1];
}Software-prefetch conversion is useful for more complicated memory access patterns. In the example above, our current pragma prefetching pass can’t deal with the complicated control flow used to determine the index into B (essentially, it doesn’t allow functions to be used to calculate addresses), so wouldn’t prefetch data for this loop, leaving performance on the table. Note that, for simplicity, I’ve assumed that i+offset will never exceed the bounds of A. If that could happen, then the second software prefetch needs to be guarded by a check, so that it cannot cause faults that would not otherwise occur. To understand the reason for prefetching at an offset within A, and why the offsets are set as they are above, see our CGO 2017 paper. Although the programmer has specified two prefetches in the code above, the first would be automatically generated by our software-prefetch-conversion pass based on the second, so only the second is actually required if the code is going to be converted to prefetch kernels.
int sum=0
for (int i=0; i<N; ++i) {
item_t *item = B[A[i]];
while (item) {
sum += item->val;
item = item->next;
}
}
on_A_load() {
pretetch(get_vaddr() + offset);
}
on_A_prefetch() {
prefetch(get_base(1) + get_data()*8);
}
on_B_prefetch() {
int *data = get_data();
prefetch(data);
prefetch(data + 4);
}This final code example is more complex still, and corresponds to an indirect access followed by a linked-list traversal. This cannot be expressed through software prefetches, so the only choice is to manually write prefetch kernels, which are shown below the loop. The first kernel is triggered when a load to the A array is observed, and initiates a prefetch at an offset in the A array. The second kernel is invoked when prefetches to the A array return data, and they use this data (which is an integer) as an index into the B array, where get_base(1) returns the base address of B. The third kernel is triggered when a prefetch to the B array or its linked list returns data to the L1 cache, and it prefetches the required value (val at offset 0 from the base of the structure) and the next pointer (at offset 4), to get the next linked-list item too. There is no way to write software prefetches for a loop such as this. Although you might be tempted to put the software prefetch for the linked-list traversal inside the while loop, at this point it is too late to be useful. What actually needs to happen is that the prefetches bring in the start of the linked list and then traverse it, for a linked list that is at some offset from the current iteration. This requires a loop within a software-prefetch directive, which is not possible to have. Hence, manually written prefetch kernels are required in this case, allowing our programmable prefetcher to react to the prefetches as they arrive, asynchronously to the main core.
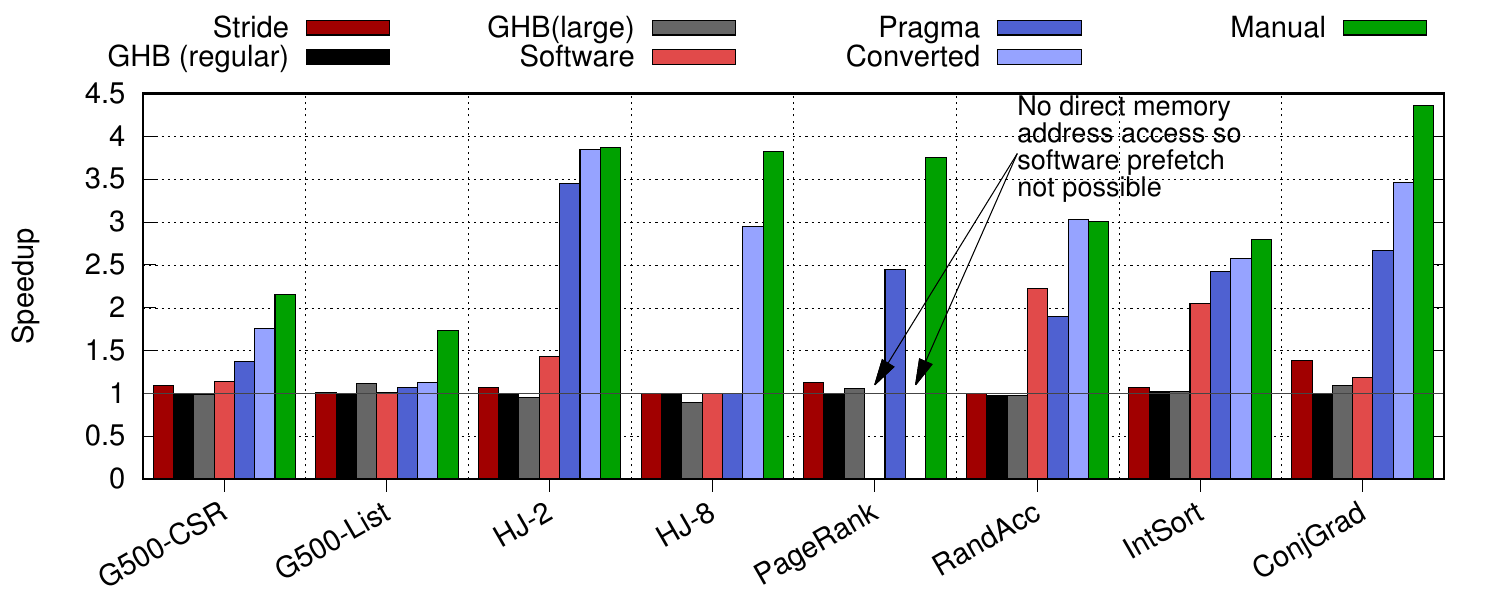
The simulated performance of our programmable prefetcher is shown above along with some other competing schemes. See the paper for an explanation of the benchmarks. The first bar, Stride, is a regular strider prefetcher; the second bar, GHB (regular), is a Markov global history buffer scheme and the third bar, GHB (large), is the same, but has 1GiB of history data, along with unlimited bandwidth and zero cycle latency to access state; the fourth, Software, uses software prefetching; the fifth, Pragma, shows the programmable prefetcher with our pragma conversion technique; the sixth, Converted, shows the same but with software-prefetch conversion; and finally the seventh, Manual, is once again the programmable prefetcher with manually written prefetch kernels. It is clear from this graph that there are significant performance gains to be realised and that the programmable prefetcher can unlock them successfully, especially when the developer takes the time to write the prefetch kernels themselves.
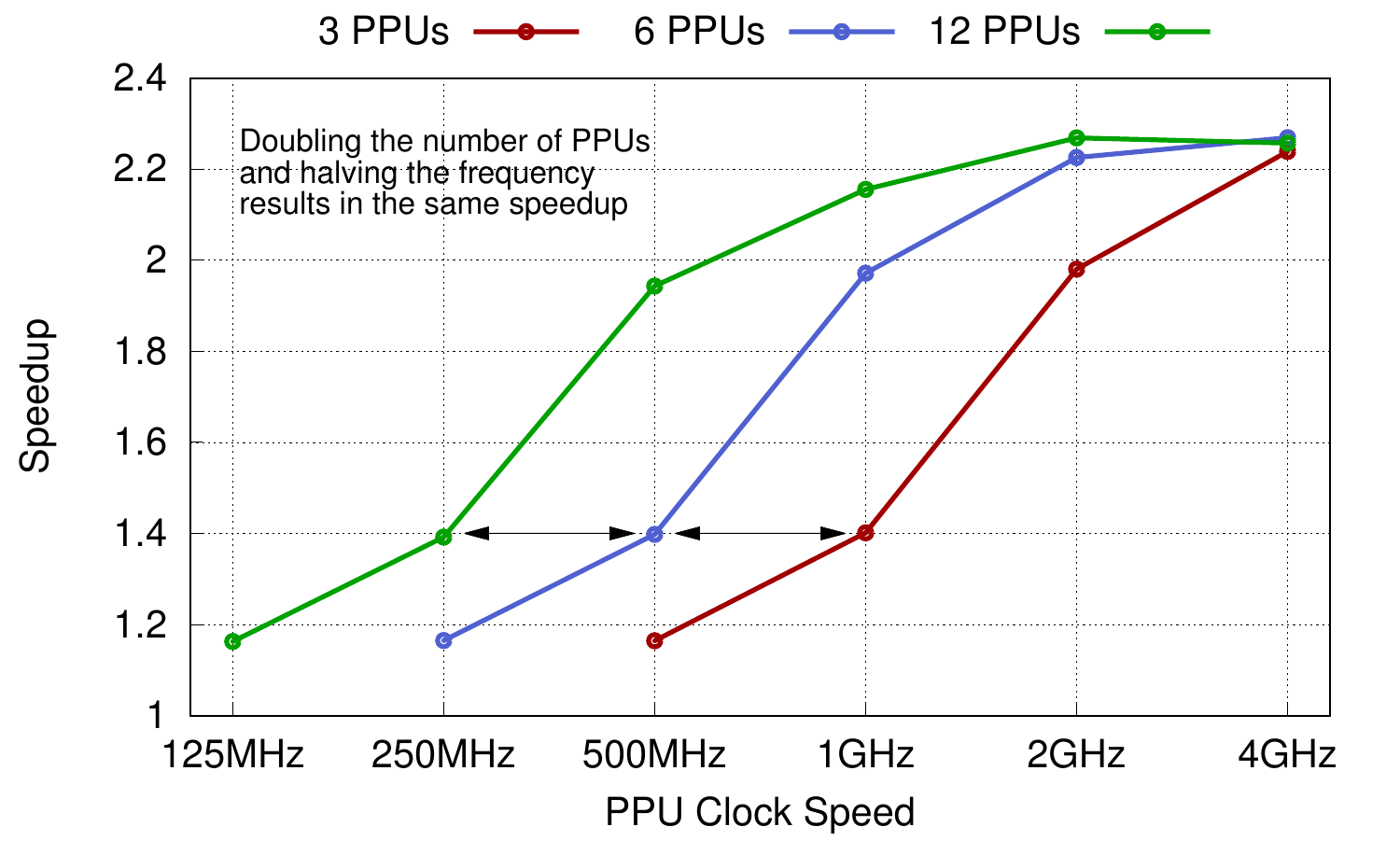 The graph on the left shows how the programmable prefetcher takes advantage of the memory-level parallelism available, in this case for the Graph500 benchmark using compressed sparse-row format. Essentially, given a particular configuration of programmable prefetch units (i.e. number and frequency), performance can be maintained by halving their number and doubling their frequency, or by doubling their number and halving their frequency. (Note that we show scaling to 4GHz but don’t ever expect the PPUs to be clocked this fast!) There is abundant parallelism available, and from an energy-efficiency standpoint, it makes sense to use a large number of very small, simple cores, rather than a few medium-complexity cores that are clocked slightly faster.
The graph on the left shows how the programmable prefetcher takes advantage of the memory-level parallelism available, in this case for the Graph500 benchmark using compressed sparse-row format. Essentially, given a particular configuration of programmable prefetch units (i.e. number and frequency), performance can be maintained by halving their number and doubling their frequency, or by doubling their number and halving their frequency. (Note that we show scaling to 4GHz but don’t ever expect the PPUs to be clocked this fast!) There is abundant parallelism available, and from an energy-efficiency standpoint, it makes sense to use a large number of very small, simple cores, rather than a few medium-complexity cores that are clocked slightly faster.
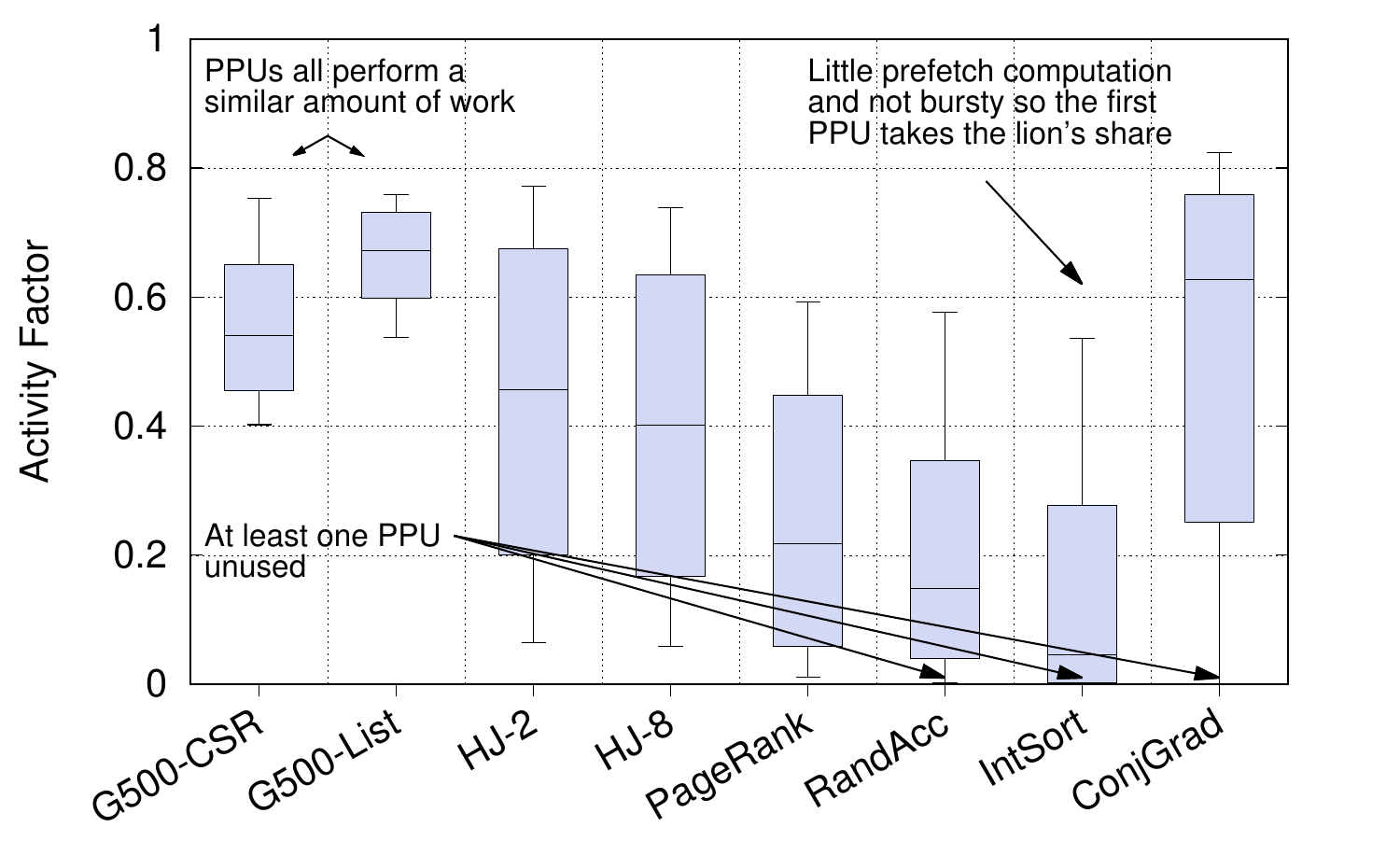 Finally, the next graph shows the fraction of time each of the PPUs runs code over the whole of each application. The scheduler picks the PPU with the lowest ID from all free PPUs to schedule observations on, so the PPU with the lowest ID is used most frequently, that with the highest is used least. It doesn’t affect performance results but does allow us to produce a graph like this; another scheduling policy could easily be used.
Finally, the next graph shows the fraction of time each of the PPUs runs code over the whole of each application. The scheduler picks the PPU with the lowest ID from all free PPUs to schedule observations on, so the PPU with the lowest ID is used most frequently, that with the highest is used least. It doesn’t affect performance results but does allow us to produce a graph like this; another scheduling policy could easily be used.
It’s clear that some applications contain more memory-level parallelism than others, or require more in-flight prefetches to obtain their speedups. The Graph500 benchmarks contain sufficient memory-level parallelism to keep all PPUs working for much of the time. For others, such as RandAcc and IntSort, one PPU tends to do far more than the others and some PPUs do no work. This is mainly because the calculations required to determine the next prefetch are simple operations that do not take up significant time on the PPU running the prefetch kernel. In fact, our programmable prefetcher is over-provisioned for these workloads and we could have used fewer PPUs or clocked them at a lower frequency (the graph shows 12 PPUs at 1GHz).
So, in summary we’ve created a programmable prefetcher, capable of running developer-written (or compiler-generated) code to generate prefetches. The hardware is event-driven, naturally fitting the way in which memory accesses and prefetches are seen by the cache hierarchy, and allowing us to take advantage of abundant memory-level parallelism in an energy-efficient manner with an array of simple microcontroller-sized cores clocked at a low frequency. This can unleash significant performance—3.0x speedup for our workloads, on average, or up to 4.4x in the best case. The paper is online now and I invite you to find out more and ask any questions you may have of it here.
