
Submitted by Timothy Jones on Tue, 09/08/2016 - 13:06
![]() This post is about my group’s second ICS paper from June this year, which describes a new single producer / single consumer (SP/SC) software queue that we developed for frequent inter-core communication. It’s faster than existing implementations and we call it Lynx. It’s available on my group’s data page.
This post is about my group’s second ICS paper from June this year, which describes a new single producer / single consumer (SP/SC) software queue that we developed for frequent inter-core communication. It’s faster than existing implementations and we call it Lynx. It’s available on my group’s data page.
Initially, we didn’t set out to create a new queue. We were experimenting with transient error detection techniques in software. Transient, or soft, errors are faults that occur sporadically within a microprocessor, causing a data value or instruction to change. They are the result of strikes to the chip from cosmic rays (or usually the secondary particles they excite) or alpha particles from chip packaging, amongst other things. Wikipedia has an article specifically about them. Soft errors are usually taken care of in memories by using error correcting codes (ECC) through special DRAM DIMMs and processor caches with ECC support. Back in 2009, following several comments he’d made about the need for ECC in caches, James Hamilton wrote a blog post about a Sigmetics publication1 that describes a field study of DRAM errors (both hard and soft) in depth.
Given existing solutions for hardware detection and correction in memories, most work on soft error detection focuses on the processor core. Although additional hardware schemes can be developed to detect transient errors, there is a body of work in the literature that aims to perform this role in software, by running duplicate copies of the application code and comparing the results to identify when execution diverges. This is nice because the programmer can determine which bits of the application are critical, and only pay the penalty of detection for those that need protection, and it avoids adding in new hardware which may itself need protecting. (Note that one good thing about ECC is that it checks itself.)
When performing error detection within software, there are basically two main options for the location of the detection or checking code. Either each thread checks itself, or each thread is partnered with a new checker thread that is responsible for detection. (There is a third option which is to farm the checking out to a totally new process, which may or may not have the same number of threads as the original.) The overall idea with these two solutions is to ensure that all memory accesses are correct. That is, that the addresses for loads and stores are correct, and that the values stored back to memory are also correct. In the former, all code that is required for generating memory addresses and stored data is replicated and placed alongside the original code that it duplicates. Checks are inserted before loads and stores to make sure that the duplicated instructions compute the same values as the originals. On a mismatch, control transfers to a handling routine which can roll back to a known good point and try again, or alert the OS / user and bail out.
In the second scheme, called redundant multithreaded error detection, a similar situation occurs. However, instead of the duplicate code and checks being created inline with the original, they are placed in a new thread that is paired with the original. The original thread sends the values it computes (addresses and stored data) to the new, checker thread so it can check against its own duplicate results. However, having the original thread wait for the result of a check before each memory access would cause a significant slowdown, due to the latencies involved in passing data between threads. Therefore, high performance is achieved by decoupling the threads from one another and allowing the checker thread to run a little behind the original, relaxing the checking conditions so that they do not need to be performed before the original makes a memory access, as long as they occur at some point in the future. This means that information flows only one way, from the original to the checker thread, breaking the cyclic dependence between the two and enabling the original to run ahead in computation. In this scenario the checker thread cannot make memory accesses itself (because it may load a value that the original has since updated), so the original thread must also pass loaded values to the checker thread for it to perform its duplicated execution.
A critical component in this type of error detection is the data structure for passing values from the original to the checker thread. The computation model naturally lends itself to a queue, since the checker will require values in the same order as the original. In fact, we can use an SP/SC queue that is optimised for just one producer and one consumer. However, this kind of queue comes with its own challenges, and state-of-the-art implementations have been tuned to reduce these as much as possible. Let’s start with an overview of the queue.
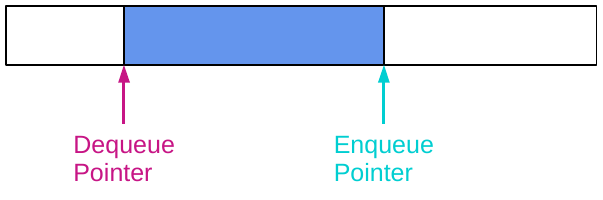 This figure shows a lock-free SP/SC queue, similar to that proposed by Leslie Lamport in his 1983 paper2. Here, the queue is an area of memory that has been reserved and acts as a ring buffer and there are two pointers into it, one for enqueue and one for dequeue. The blue part of the queue shows the region between the two pointers that contains data; unfilled parts of the queue are free space. Both pointers move from left to right as items are placed in the queue (by enqueue) and removed (by dequeue). More items can be added to the queue as long as
This figure shows a lock-free SP/SC queue, similar to that proposed by Leslie Lamport in his 1983 paper2. Here, the queue is an area of memory that has been reserved and acts as a ring buffer and there are two pointers into it, one for enqueue and one for dequeue. The blue part of the queue shows the region between the two pointers that contains data; unfilled parts of the queue are free space. Both pointers move from left to right as items are placed in the queue (by enqueue) and removed (by dequeue). More items can be added to the queue as long as (enqPtr + 1)%size != deqPtr (i.e. the queue isn’t full) and taken off the queue as long as deqPtr != enqPtr (i.e. the queue isn’t empty).
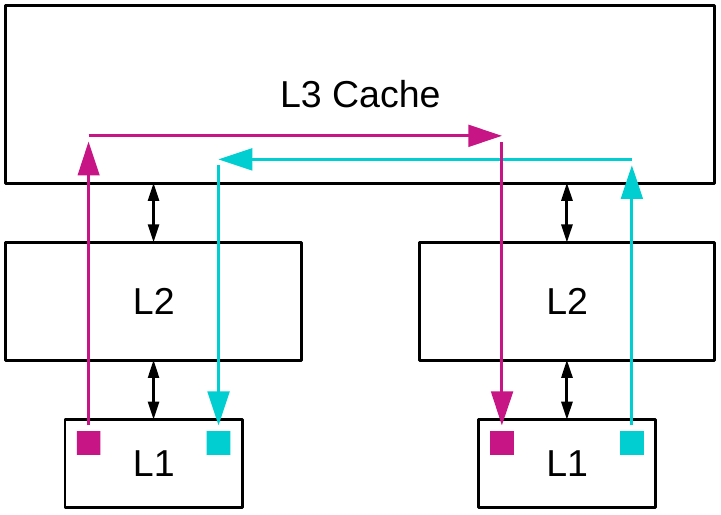 The first issue with this kind of queue is cache ping-pong, as shown in this figure. This name refers to the queue control variables being repeatedly copied from one cache to another to check the enqueue and dequeue conditions, then being invalidated when the pointers need updating. For example, the dequeue pointer (in pink) starts off being readable and writeable in the left-hand cache, whose core is running the checker thread. When the original thread wants to push a value into the queue, it must read the dequeue pointer to test for space, so the cache coherence protocol automatically removes write access from the left-hand L1, copies the pointer into the private L2 and shared L3, then down into the right-hand L2 and L1, where this thread is given read access. Once the dequeue operation removes an item from the list, it updates the dequeue pointer, meaning that the coherence protocol must invalidate the copy in the right-hand L1 cache. These operations can be quite costly, as we show in our ISCA 2014 HELIX paper, where an Intel Ivy Bridge processor can take 75 cycles to transfer data from core to core.
The first issue with this kind of queue is cache ping-pong, as shown in this figure. This name refers to the queue control variables being repeatedly copied from one cache to another to check the enqueue and dequeue conditions, then being invalidated when the pointers need updating. For example, the dequeue pointer (in pink) starts off being readable and writeable in the left-hand cache, whose core is running the checker thread. When the original thread wants to push a value into the queue, it must read the dequeue pointer to test for space, so the cache coherence protocol automatically removes write access from the left-hand L1, copies the pointer into the private L2 and shared L3, then down into the right-hand L2 and L1, where this thread is given read access. Once the dequeue operation removes an item from the list, it updates the dequeue pointer, meaning that the coherence protocol must invalidate the copy in the right-hand L1 cache. These operations can be quite costly, as we show in our ISCA 2014 HELIX paper, where an Intel Ivy Bridge processor can take 75 cycles to transfer data from core to core.
The second issue is with false sharing. When the checker thread runs only a short distance behind the original, the enqueue and dequeue pointers can become so close together that they point into the same cache line. In this case, the coherence protocol continuously invalidates the line in the checker thread’s cache so as to give write access to the enqueue thread, then remove write access in this cache so as to allow the checker thread to dequeue an item. This continues for each line in the cache, or until the checker thread falls far enough behind the original.
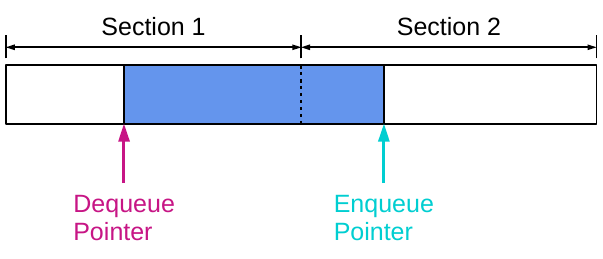 To combat these issues, a number of researchers have developed multi-section queues. This design splits the queue into several disjoint areas and only allows a maximum of one pointer to target each section at a time. When a thread reaches the end of its section, it must wait for the other thread to leave the next section before it can continue. This reduces the cache ping-pong effect, so that it only happens at section boundaries, and removes false sharing completely (as long as the sections are larger than a cache line).
To combat these issues, a number of researchers have developed multi-section queues. This design splits the queue into several disjoint areas and only allows a maximum of one pointer to target each section at a time. When a thread reaches the end of its section, it must wait for the other thread to leave the next section before it can continue. This reduces the cache ping-pong effect, so that it only happens at section boundaries, and removes false sharing completely (as long as the sections are larger than a cache line).
So, at this point we had implemented our redundant multithreaded error detection scheme with a state-of-the-art multi-section queue, but we hadn’t achieved the kind of performance we wanted. We therefore started looking at where the performance bottlenecks were in the hope of optimising them. The queue seemed to be an area that was causing issues, yet it seemed difficult to work out how we could improve on this design. So we looked closely at exactly what is happening during the enqueue function. Here it is in x86_64 assembly code:
1 lea rax, [rdx+8] ; Increment pointer 2 mov QWORD PTR [rdx], rcx ; Store to queue 3 mov rdx, rax ; Compiler's copy 4 and rdx, ROTATE_MASK ; Rotate pointer 5 test eax, SECTION_MASK ; End of section 6 jne .L2 ; Skip sync code
There are six instructions on the critical path that are executed every time an enqueue is performed (these are actually inlined into the positions we push values into the queue in the original thread, rather than being part of the enqueue function). In addition, there is the sync code, that checks whether the thread can move into the next section and waits if not, which comes after this but is not shown because it is long and rarely executed. We started to wonder what impact these six instructions have on performance.
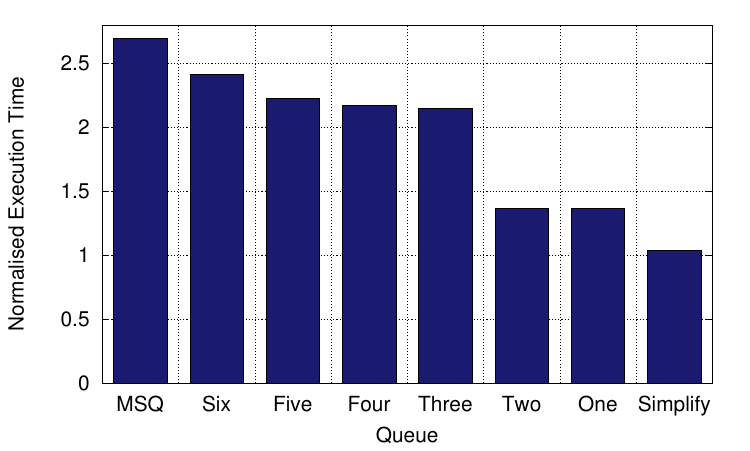 Turns out it was quite a lot! This graph shows the execution time of different scenarios for the Salsa benchmark from the LLVM test suite, normalised to native execution (i.e. single-threaded and no error detection). This is a memory-intensive benchmark, so is sensitive to the queue’s performance since it contains a large number of loads and stores.
Turns out it was quite a lot! This graph shows the execution time of different scenarios for the Salsa benchmark from the LLVM test suite, normalised to native execution (i.e. single-threaded and no error detection). This is a memory-intensive benchmark, so is sensitive to the queue’s performance since it contains a large number of loads and stores.
On the left is the performance of this application with redundant multithreaded error detection using the state-of-the-art multi-section queue (MSQ). Next to that are six bars that represent the performance when we look only at the original thread, but the enqueue operation contains varying numbers of those six instructions above. (Actually, for the six-instruction case, we had to replace the final jne with a mov because the compiler kept optimising it away; otherwise all other instructions are as above.) Finally, on the right, is a bar representing the performance of that original thread when we perform an instruction simplification pass only, that separates out address calculations from the loads and stores, which is necessary to correctly perform error detection.
Moving from six instructions for enqueue through to one, we removed first removed the mov at line 6 (that used to be a jne), then the test, then the and, then the mov from line 3, and finally the lea. It is clear that it is extremely beneficial to reduce the number of instructions used to push data into the queue. So we looked at those instructions and thought. We really thought hard about what they were doing and how we could possibly get rid of them! But it was tricky, because they are needed to make sure a thread doesn’t go off the end of the queue, and to determine when it reaches the end of a section and needs to synchronise with the other. So we looked some more and thought some more. And then we had our light-bulb moment!
The key idea behind Lynx is to shift the burden of identifying the end of the queue and the end of a section off the critical path. They are not common events, yet they are checked every time a push occurs. In fact, as I describe below, Lynx not only removes the checking from the critical path, but also moves it into hardware, rather than performing it in software, thus enabling checks on every access but without the instruction overheads.
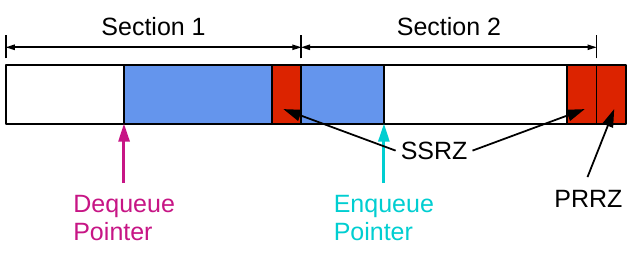 Lynx modifies this state-of-the-art multi-section queue by adding in what we call synchronisation red zones. These are areas of memory that the application is not allowed to read from or write to. They are the size of a memory page (so 4KiB in our system) and are managed by the queue itself. There are two section synchronisation red zones (SSRZs), one at the end of each section, and a pointer rotation red zone (PRRZ), which is at the end of the queue.
Lynx modifies this state-of-the-art multi-section queue by adding in what we call synchronisation red zones. These are areas of memory that the application is not allowed to read from or write to. They are the size of a memory page (so 4KiB in our system) and are managed by the queue itself. There are two section synchronisation red zones (SSRZs), one at the end of each section, and a pointer rotation red zone (PRRZ), which is at the end of the queue.
Every access to the queue (indeed, every access to memory) must pass through the translation lookaside buffer (TLB), both to translate the virtual address that the application sees into the physical address of the actual memory location to access, and to check the access permissions that the application has for that memory page. (As a different aside, trying to separate out the virtual memory system from security checking is something being worked on here in Cambridge with the CTSRD project.) We take advantage of this within the queue, by setting up the red zones at initialisation time, and marking them as non-readable and non-writeable. When a thread tries to access one of them, the TLB catches the access and traps into the operating system, which raises a segmentation fault. We define our own signal handler that is then called and it identifies which red zone has been accessed and deals with it appropriately, including all of the synchronisation required for allowing threads to move between queue sections and preventing the them from falling off the end of the queue by rotating their pointer back to the start. In this way, we reduce the overhead of enqueuing data down to just two instructions—lines 1 and 2 in the code above.
The paper gives much more information, including how the SSRZs move through the queue and what the signal handler’s synchronisation code looks like, as well as our evaluation of the options available to control the multi-section queue and our results from running Lynx. The only question remaining is how Salsa performs using Lynx instead of the multi-section queue. Well, running redundant multithreaded error detection using Lynx, its normalised performance is 1.75× the baseline, which is between the performance of two and three instructions shown in the graph above. The additional overheads come from having to wait for the checker thread before entering new sections (the same reason MSQ is slower than using six instructions). In comparison, MSQ has an execution time of 2.70× the baseline, showing that Lynx can significantly improve performance by shifting work off the critical path.
- Bianca Schroeder, Eduardo Pinheiro, and Wolf-Dietrich Weber. DRAM errors in the wild: a large-scale field study. ACM SIGMETRICS Performance Evaluation Review. Vol. 37. No. 1. ACM, 2009. ↩
- Leslie Lamport. Specifying Concurrent Program Modules. Transactions on Programming Languages and Systems, 5(2), 1983. ↩
