
Submitted by Timothy Jones on Wed, 12/07/2017 - 14:20
Over the past few years I’ve become increasingly interested in dynamic binary modification (DBM) tools, so much so that I supervise a PhD student who is trying to parallelise binaries using one, and am just starting work on a grant that continues and extends this work. On Intel’s architecture, Pin is probably the most famous tool, and one that I had most experience of in the past. (As an aside, Pin is a dynamic binary instrumentation tool, but I’m going to use modification instead of instrumentation throughout this post, since modification subsumes instrumentation and I’m more interested in optimisation than just analysis.) However, it’s closed source and only targets Intel’s ISAs. Another option is DynamoRIO, a tool that came out of a collaboration between HP Labs and MIT, from the original Dynamo system (a brief history is available). This has support for multiple ISAs, not just x86 but ARM’s 32-bit architecture and, more recently, AArch64. This is an attractive tool for researchers due to the multiple-ISA support and because it is open source. However, there is also another open source DBM for AArch64, called Mambo, which comes from my friends at the University of Manchester.
I was interested to see the differences in performance between these two open-source systems. DynamoRIO is far more mature, but the AArch64 support is still very much under development (and at the time of writing, I’m told that the focus is still on correctness rather than performance). Mambo is younger and specialised to ARM’s ISAs but doesn’t yet have the range of support available in DynamoRIO for writing modification tools (plugins, in Mambo terminology, or clients for DynamoRIO).
To perform my comparison, I cross-compiled as many SPEC CPU 2006 benchmarks as I could on an AMD system using the gcc-aarch64-linux-gnu package (and siblings for g++ and gfortran) with optimisation level O2, and ignoring those that failed. I had to cross-compile because I don’t have the SPEC tools for the AArch64 system and didn’t want to go through the pain of trying to compile them. I ran each benchmark three times using the reference input and took the average—this wasn’t meant to be a paper-quality experimental methodology. I used the git repositories for both DBMs on the 30th May, with DynamoRIO it was commit b640fdbd47d7404e4c8b7175daa31cf5d6d9fb2d and from Mambo it was commit 46a9b402b1b12645194c888e2b6eef9cbc4bd953. I ran on an NVIDIA TX1 board with a Cortex-A57 at 1.9GHz, with a 32KiB L1 data cache, 2MiB L2 and 4GiB LPDDR4 memory. In fact, it’s the board we used in our software prefetching paper.
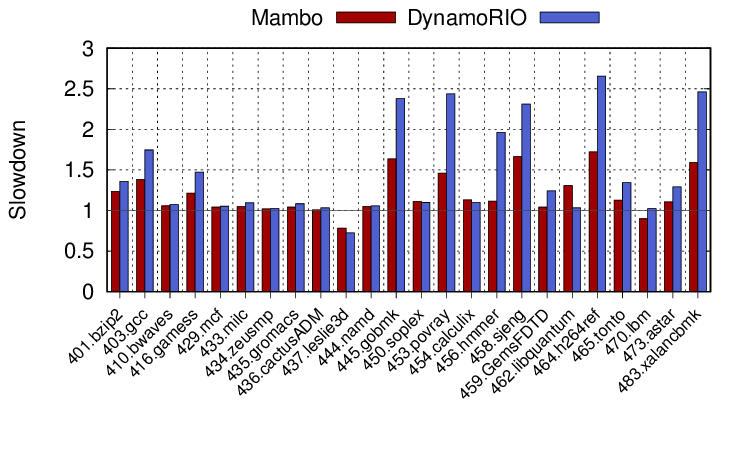 This first graph shows the performance of each benchmark running under both DBM systems compared to native execution. Mambo is clearly massively better for some benchmarks and DynamoRIO only wins on a few (leslie3d, soplex (just), calculix and libquantum). The overheads are significant for some of these workloads, going beyond 1.5x in the worst case for Mambo, and beyond 2.5x for DynamoRIO.
This first graph shows the performance of each benchmark running under both DBM systems compared to native execution. Mambo is clearly massively better for some benchmarks and DynamoRIO only wins on a few (leslie3d, soplex (just), calculix and libquantum). The overheads are significant for some of these workloads, going beyond 1.5x in the worst case for Mambo, and beyond 2.5x for DynamoRIO.
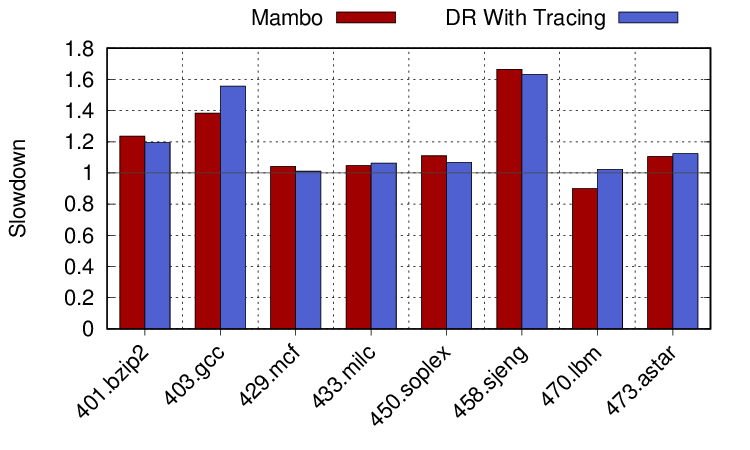 Now, DynamoRIO for AArch64 doesn’t yet have trace support. It’s still under development, but available in the branch I pulled from. Because it’s experimental, it doesn’t work for all workloads (and sadly not many of those we’re interested in from before), but here are the results when running on the benchmarks where it does work. It can make quite a difference. The largest differences are in bzip2, which decreases its slowdown from 1.4x to 1.2x, gcc is 1.7x to 1.5x, sjeng reduces from 2.3x to 1.6x and astar goes from 1.3x to 1.1x. So tracing support does really help for sjeng, in particular. What about those other benchmarks though, is there any reason why they might have such large slowdowns? The next two graphs show one possible reason.
Now, DynamoRIO for AArch64 doesn’t yet have trace support. It’s still under development, but available in the branch I pulled from. Because it’s experimental, it doesn’t work for all workloads (and sadly not many of those we’re interested in from before), but here are the results when running on the benchmarks where it does work. It can make quite a difference. The largest differences are in bzip2, which decreases its slowdown from 1.4x to 1.2x, gcc is 1.7x to 1.5x, sjeng reduces from 2.3x to 1.6x and astar goes from 1.3x to 1.1x. So tracing support does really help for sjeng, in particular. What about those other benchmarks though, is there any reason why they might have such large slowdowns? The next two graphs show one possible reason.
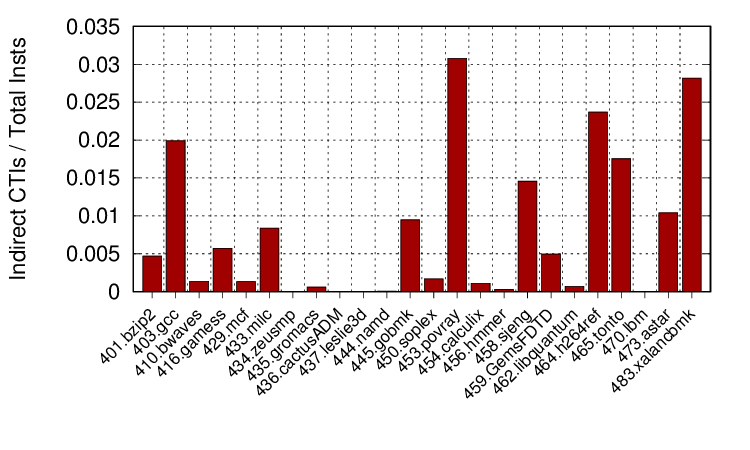 The first graph shows the fraction of dynamic instructions that are indirect control transfer instructions (CTIs) for each benchmark. Indirect CTIs are those where the destination is not encoded in the instruction, but is obtained from a register instead. That means that an indirect CTI can actually target multiple different addresses during execution and are difficult for a DBM to optimise (direct CTIs, on the other hand, have a single target and can be linked together easily in the DBM’s code cache). These instructions are therefore a source of performance loss, unless handled efficiently. Indirect CTIs occur from calls through function pointers, function returns, compiler-generated jump tables from switch statements and, in object-oriented languages, virtual function calls. I obtained these values through a DynamoRIO client that is available on my open source code and data page, as is the output data set in case anyone else wants to make use of it. As can be seen although the fraction of dynamic instructions that are indirect CTIs is small, it varies across programs. Those that have a high fraction, such as povray, h264ref and xalancbmk, have large slowdowns with DynamoRIO.
The first graph shows the fraction of dynamic instructions that are indirect control transfer instructions (CTIs) for each benchmark. Indirect CTIs are those where the destination is not encoded in the instruction, but is obtained from a register instead. That means that an indirect CTI can actually target multiple different addresses during execution and are difficult for a DBM to optimise (direct CTIs, on the other hand, have a single target and can be linked together easily in the DBM’s code cache). These instructions are therefore a source of performance loss, unless handled efficiently. Indirect CTIs occur from calls through function pointers, function returns, compiler-generated jump tables from switch statements and, in object-oriented languages, virtual function calls. I obtained these values through a DynamoRIO client that is available on my open source code and data page, as is the output data set in case anyone else wants to make use of it. As can be seen although the fraction of dynamic instructions that are indirect CTIs is small, it varies across programs. Those that have a high fraction, such as povray, h264ref and xalancbmk, have large slowdowns with DynamoRIO.
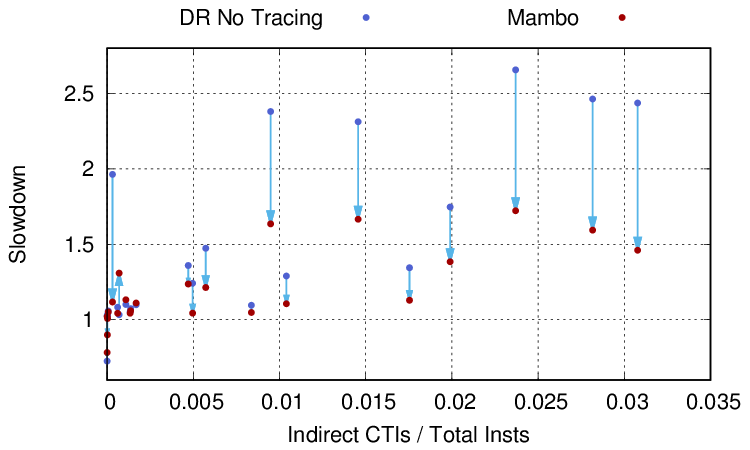 This next graph is a scatter plot that shows this relationship more clearly, for both DynamoRIO and Mambo. Arrows show the change between the performance of a benchmark under DynamoRIO to that under Mambo. To a large extent, those benchmarks on the left of the graph (a low fraction of dynamic CTIs) have good performance under both DBMs. The main exception is hmmer, which has indirect CTIs as 0.0003x of its dynamic instructions, but nearly a 2x slowdown with DynamoRIO and only 1.1x with Mambo. However, in general, the further towards the right of the graph a benchmark is, with increasing fractions of indirect CTIs, the larger DynamoRIO’s slowdowns become. This suggests that DynamoRIO is particularly bad at optimising these indirect CTIs whereas Mambo is pretty good. The latter should be expected: the abstract of the Mambo paper explicitly states that it contains novel optimisations for indirect branches.
This next graph is a scatter plot that shows this relationship more clearly, for both DynamoRIO and Mambo. Arrows show the change between the performance of a benchmark under DynamoRIO to that under Mambo. To a large extent, those benchmarks on the left of the graph (a low fraction of dynamic CTIs) have good performance under both DBMs. The main exception is hmmer, which has indirect CTIs as 0.0003x of its dynamic instructions, but nearly a 2x slowdown with DynamoRIO and only 1.1x with Mambo. However, in general, the further towards the right of the graph a benchmark is, with increasing fractions of indirect CTIs, the larger DynamoRIO’s slowdowns become. This suggests that DynamoRIO is particularly bad at optimising these indirect CTIs whereas Mambo is pretty good. The latter should be expected: the abstract of the Mambo paper explicitly states that it contains novel optimisations for indirect branches.
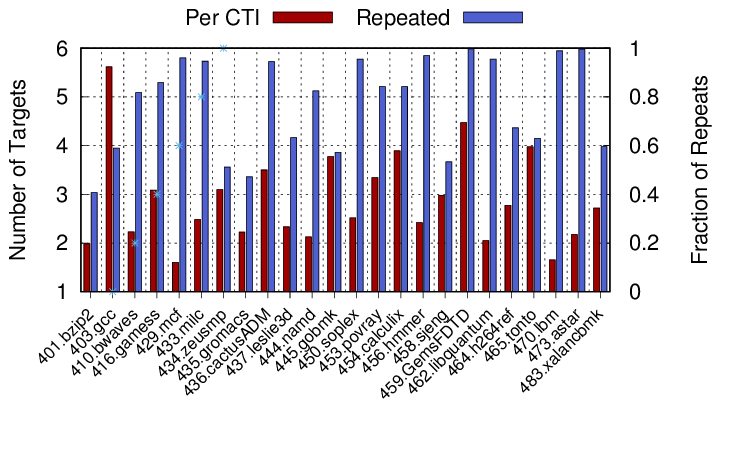 The last graph I’d like to show looks into these indirect CTIs a little more. For each indirect CTI I recorded the number of different target addresses it had and then how many times consecutive dynamic instances of it targeted the same address. In other words, given a particular indirect CTI, how many times it jumped to the same instruction as it did last time. The Per CTI bar (the left y axis) shows the average number of targets per indirect CTI whereas the Repeated bar (the right y axis) shows the average fraction of time that consecutive instances of the same indirect CTI targeted the same address. If we consider first the average number of targets each indirect CTI has, it appears quite low, but this masks a wide range. Most indirect CTIs have just one target, but there is one in xalancbmk that has 1241 unique target addresses!
The last graph I’d like to show looks into these indirect CTIs a little more. For each indirect CTI I recorded the number of different target addresses it had and then how many times consecutive dynamic instances of it targeted the same address. In other words, given a particular indirect CTI, how many times it jumped to the same instruction as it did last time. The Per CTI bar (the left y axis) shows the average number of targets per indirect CTI whereas the Repeated bar (the right y axis) shows the average fraction of time that consecutive instances of the same indirect CTI targeted the same address. If we consider first the average number of targets each indirect CTI has, it appears quite low, but this masks a wide range. Most indirect CTIs have just one target, but there is one in xalancbmk that has 1241 unique target addresses!
If we look at applications which have a high slowdown with both DBMs (>1.5x, which are gobmk, sjeng, h264ref and xalancbmk), there is definite correlation between slowdown and number of CTIs (from the graph above) but doesn’t seem to be much between the number of targets and that slowdown. However, if we consider the fraction of targets that are the same between consecutive instances of the same indirect CTI, then there does seem to be a slight pattern, with each seeing the same target approximately 60% of the time. Although it’s difficult to draw conclusions from this alone, it is worth investigating further.
Finally, we might wonder why Mambo is better than DynamoRIO, in general. There appear to be a number of reasons. First, Mambo stores the pointer to its context as a global variable, rather than stealing a register from the application, which obviously removes the need to do anything when this stolen register is used by the program, as DynamoRIO must. Second, Mambo does not deal with applications where a branch range exceeds 128MB, which means fewer checks are necessary. Third, Mambo does not switch stack space during its dispatch or signal handler, assuming the stack frame above the stack pointer is not used by the application. And fourth, Mambo does not support full isolation of application contexts. For example, if it is in the middle of translating a malloc() function call from the original application, it can’t perform a malloc() from within the Mambo core or its plugins. In general we can say that DynamoRIO sacrifices performance to allow transparent instrumentation on different types of application, whereas Mambo is a binary translator aiming for performance on simple programs.
In summary then, these two open source DBMs provide good performance for the majority of the SPEC CPU 2006 benchmarks on AArch64, although Mambo is generally better than DynamoRIO. Mambo’s indirect CTI optimisations seem to help, as does DynamoRIO’s trace support (when it works). However, there are still workloads where the overhead is high, which may still be due to the indirect CTIs, and more work needs to be done to understand whether these really are the source of slowdown.
Thanks to Kevin Zhou for comments on DBT implementations and suggestions on my initial draft.
